
Ph.D. Student in Computer Science
Dongfu Jiang | 姜东甫
AI/NLP researcher working on LLM/VLM post-training, multimodal evaluation, and agentic tool-use systems.
University of Waterloo · Waterloo, Canada · Vector Institute;
- LLM/VLM Post-Training
- Evaluation & Benchmarks
- Agentic Systems
I am on the job market for 2026!
Please feel free to reach out if you find my background a good fit for your organization.
Research Experience at

About
I am a Ph.D. student in Computer Science at the University of Waterloo. I am affiliated with TIGER-Lab and the Vector Institute, where I am advised by Prof. Wenhu Chen. I expect to graduate in June 2026. Before Waterloo, I received my B.E. in Computer Science from Zhejiang University, where I was advised by Prof. Zhou Zhao.
My recent research experience includes NVIDIA ADLR in Santa Clara, the Allen Institute for AI in Seattle, SeaAI in Singapore, and earlier collaboration with the University of Southern California. My work has been recognized with an Outstanding Paper Award at TMLR 2025 for Mantis and a Best Paper Finalist / Oral at CVPR 2024 for MMMU. Across these roles, I have worked on post-training, evaluation, and agentic systems, with several projects later adopted or cited by follow-up model, benchmark, and tooling efforts.
My research goal is to build multimodal language agents that can reason, use tools, and collaborate with humans in open-ended settings. More broadly, I am interested in turning capable foundation models into practical systems through stronger post-training methods, better benchmarks, and reusable research infrastructure. My recent research interests include:
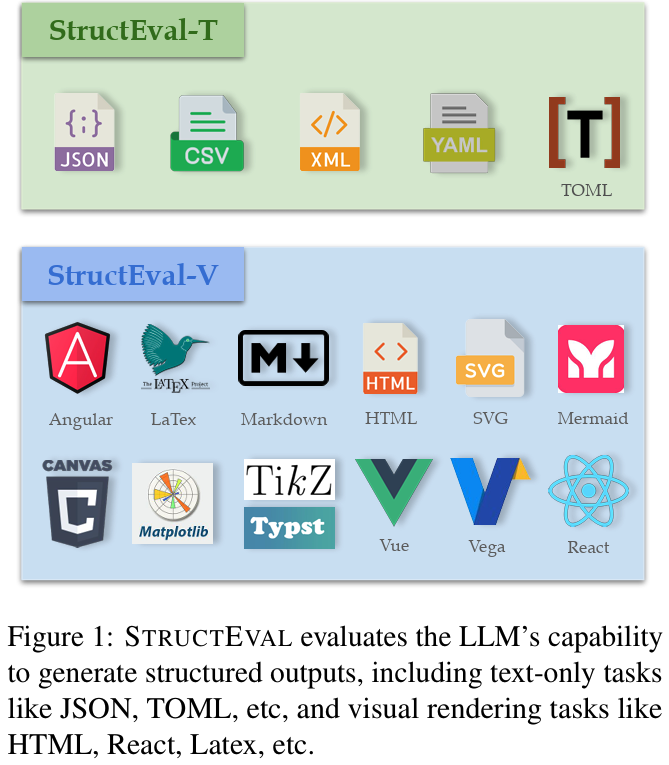
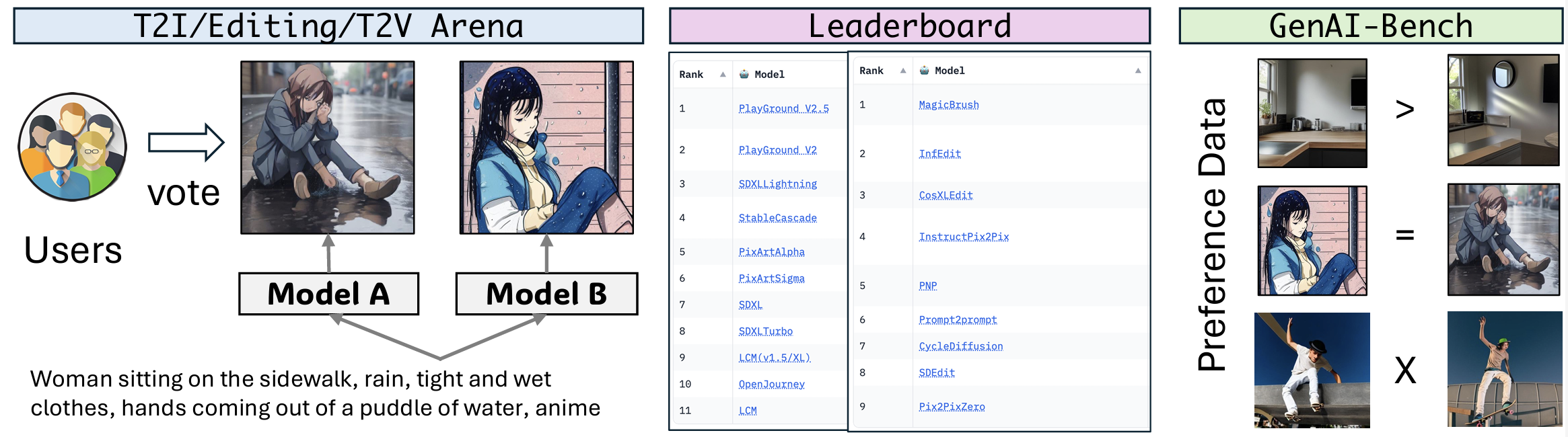
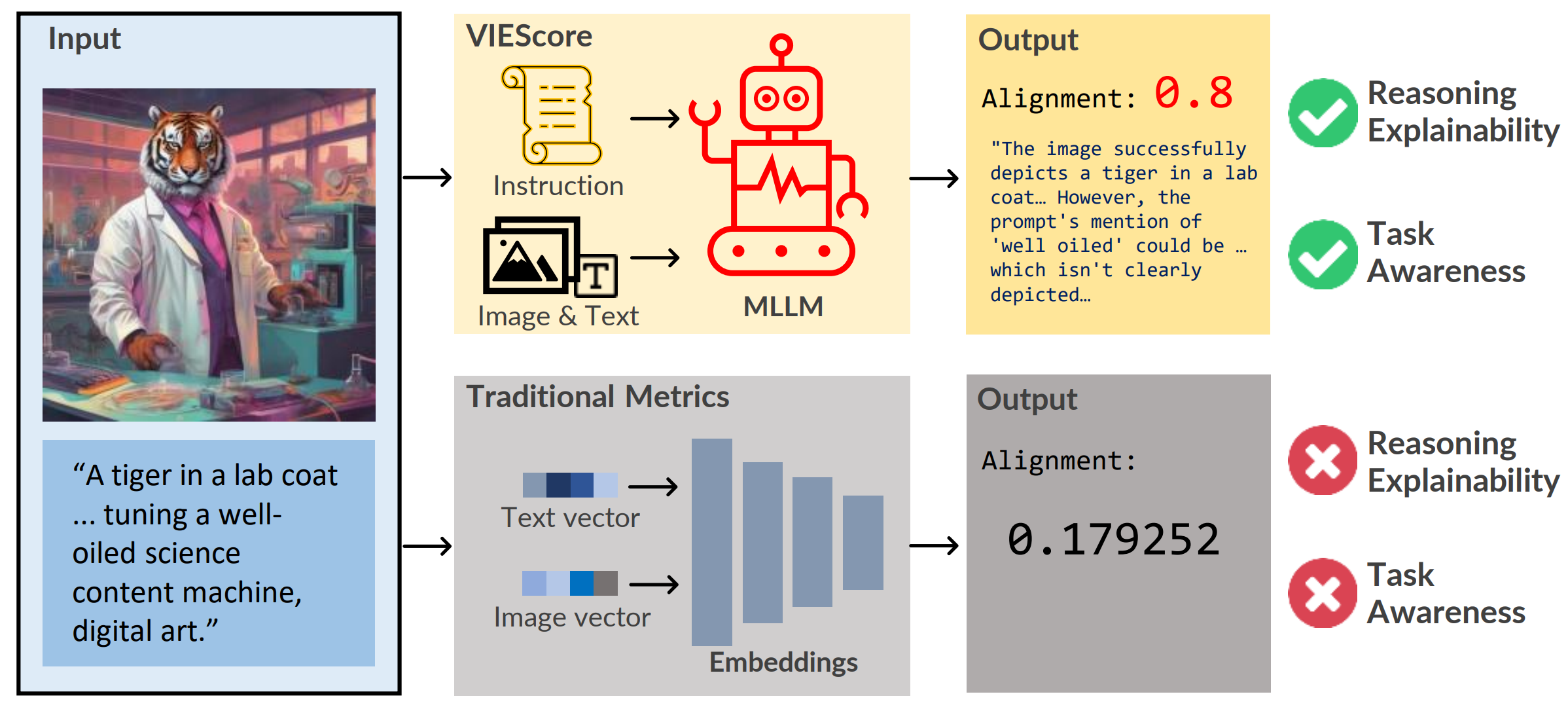
- Evaluation and benchmarks: MMMU, VIEScore, WildVision, GenAI Arena, MEGA-Bench, TIGERScore, StructEval
- LLM/VLM post-training: Nemotron 3 Super, Mantis, AceCoder, General-Reasoner, Critique-Coder
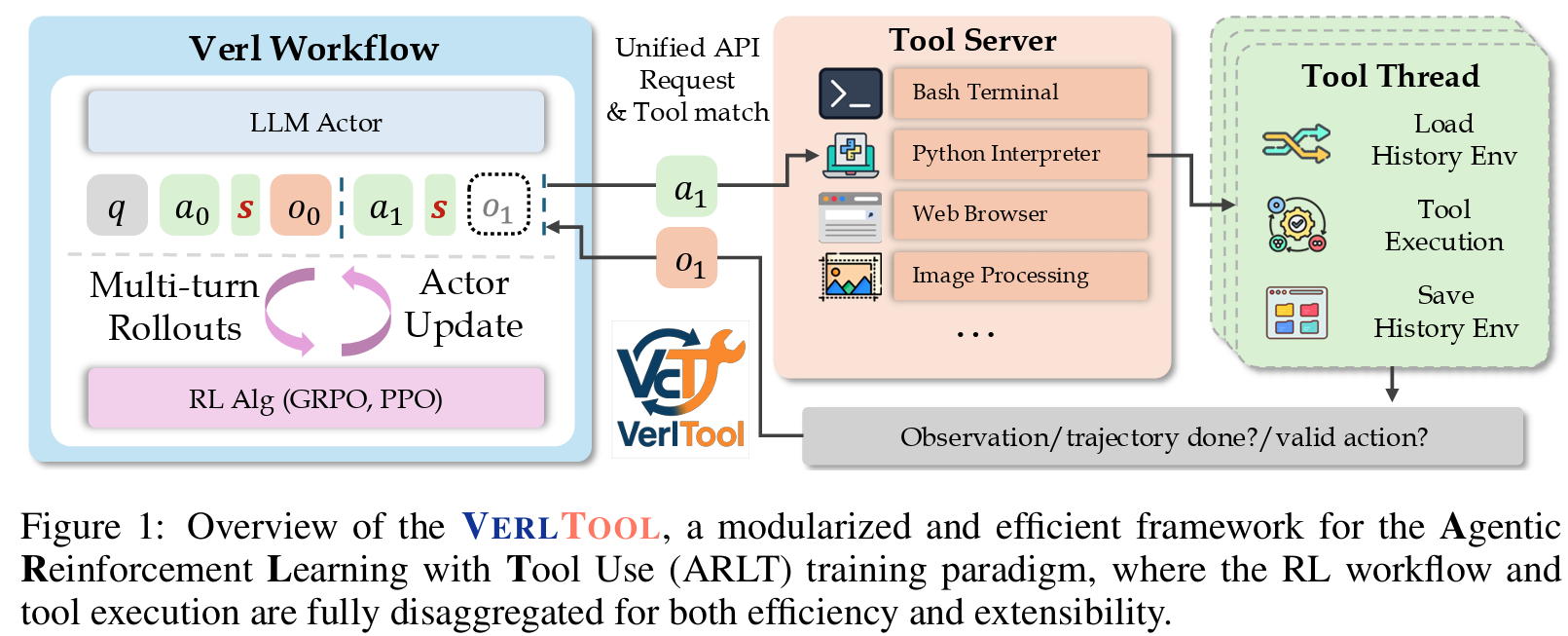
- Agentic Systems: VerlTool, OpenResearcher, Nemotron 3 Super, LLM-Blender
I am actively looking for full-time positions in industry research or engineering. Feel free to reach out by email if my background looks relevant.
Recent News
All news MMMU is accepted to CVPR 2024 oral presentation! MMMU for evaluating multi-modal models!
MMMU is accepted to CVPR 2024 oral presentation! MMMU for evaluating multi-modal models! Publications (*, + indicate equal contribution)
Google ScholarNo publications match this topic yet.
2026
- ReportMar 2026Technical report, March 11, 2026
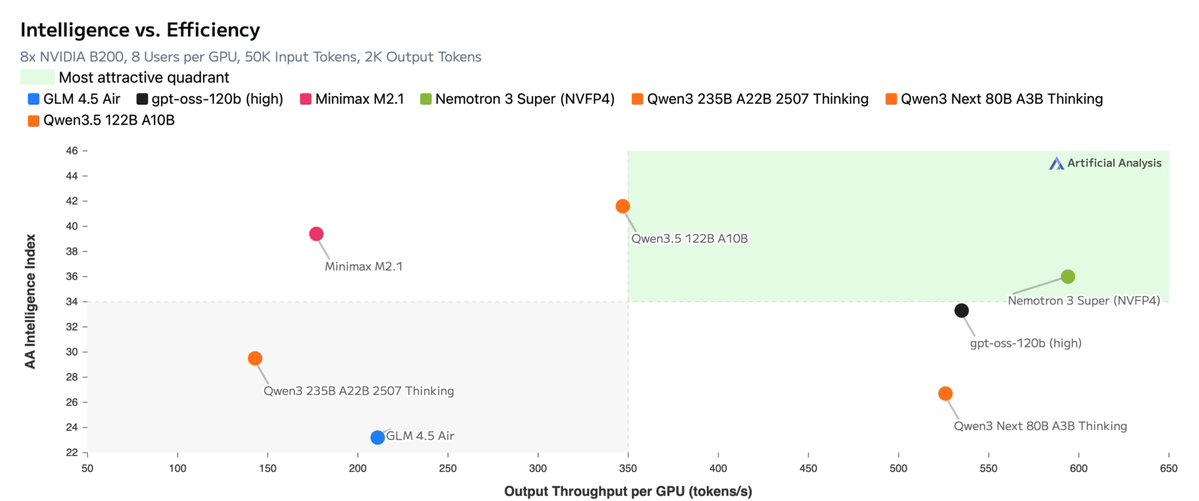
- BlogFeb 2026Blog post, February 9, 2026
- In The Fourteenth International Conference on Learning Representations, Feb 2026
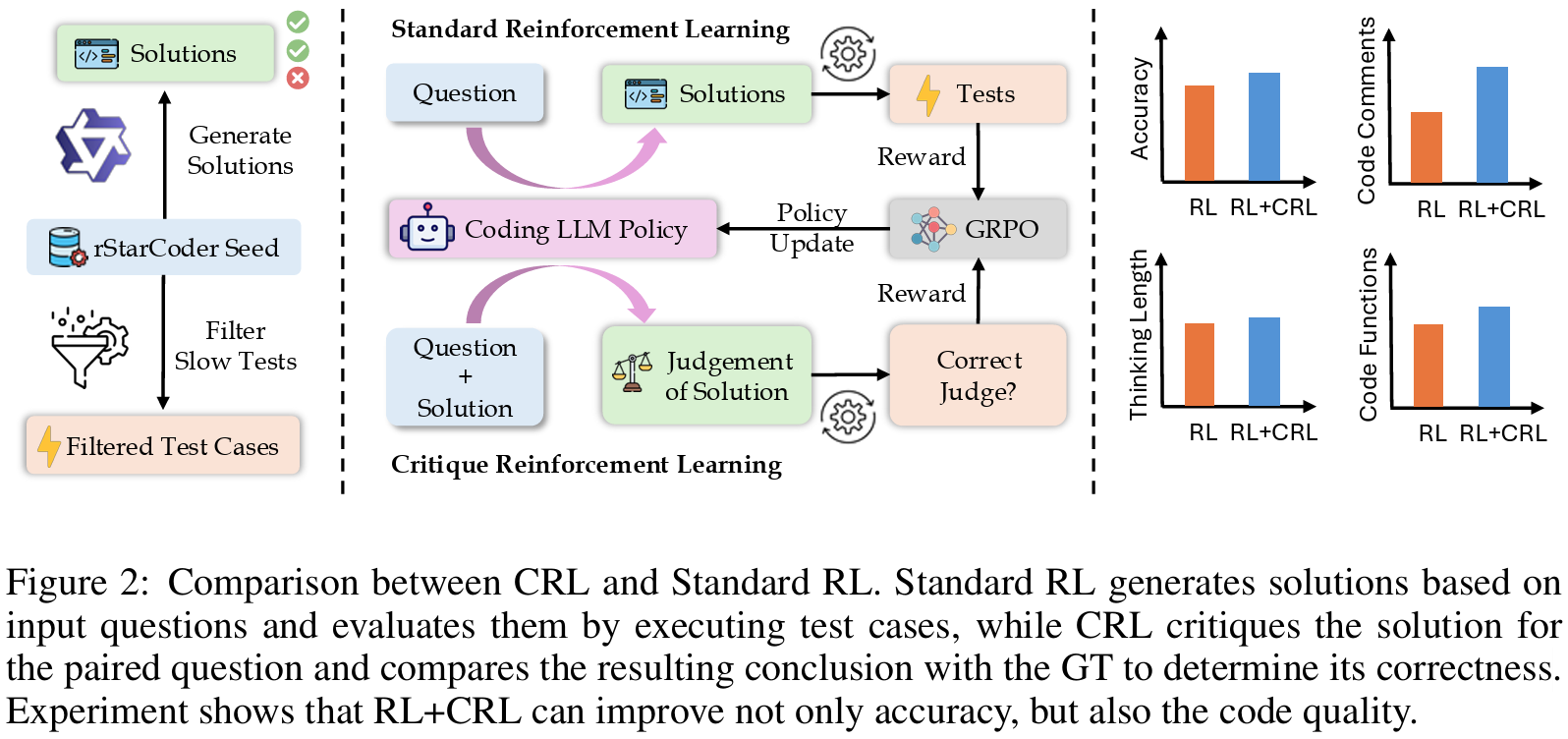
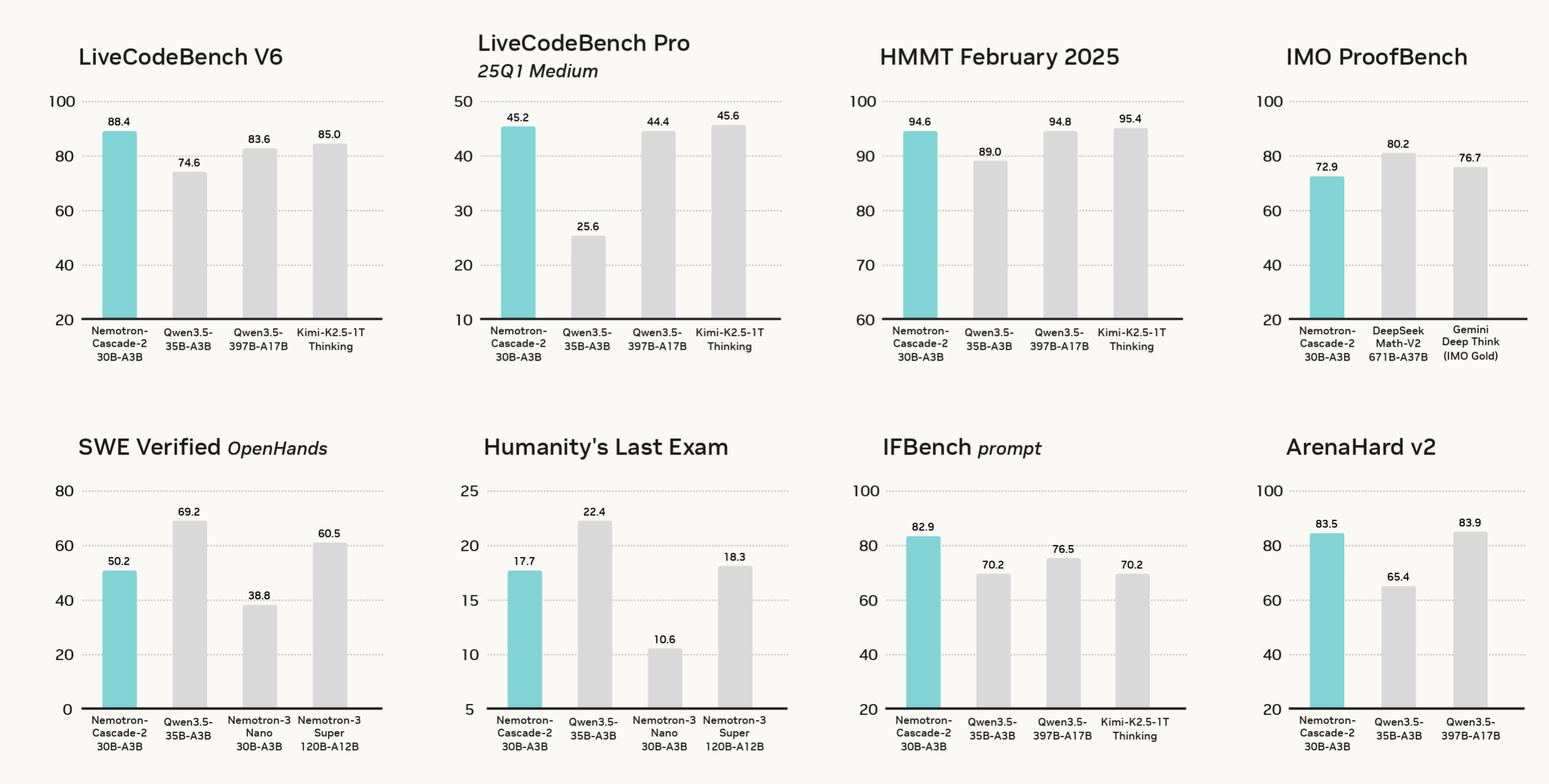
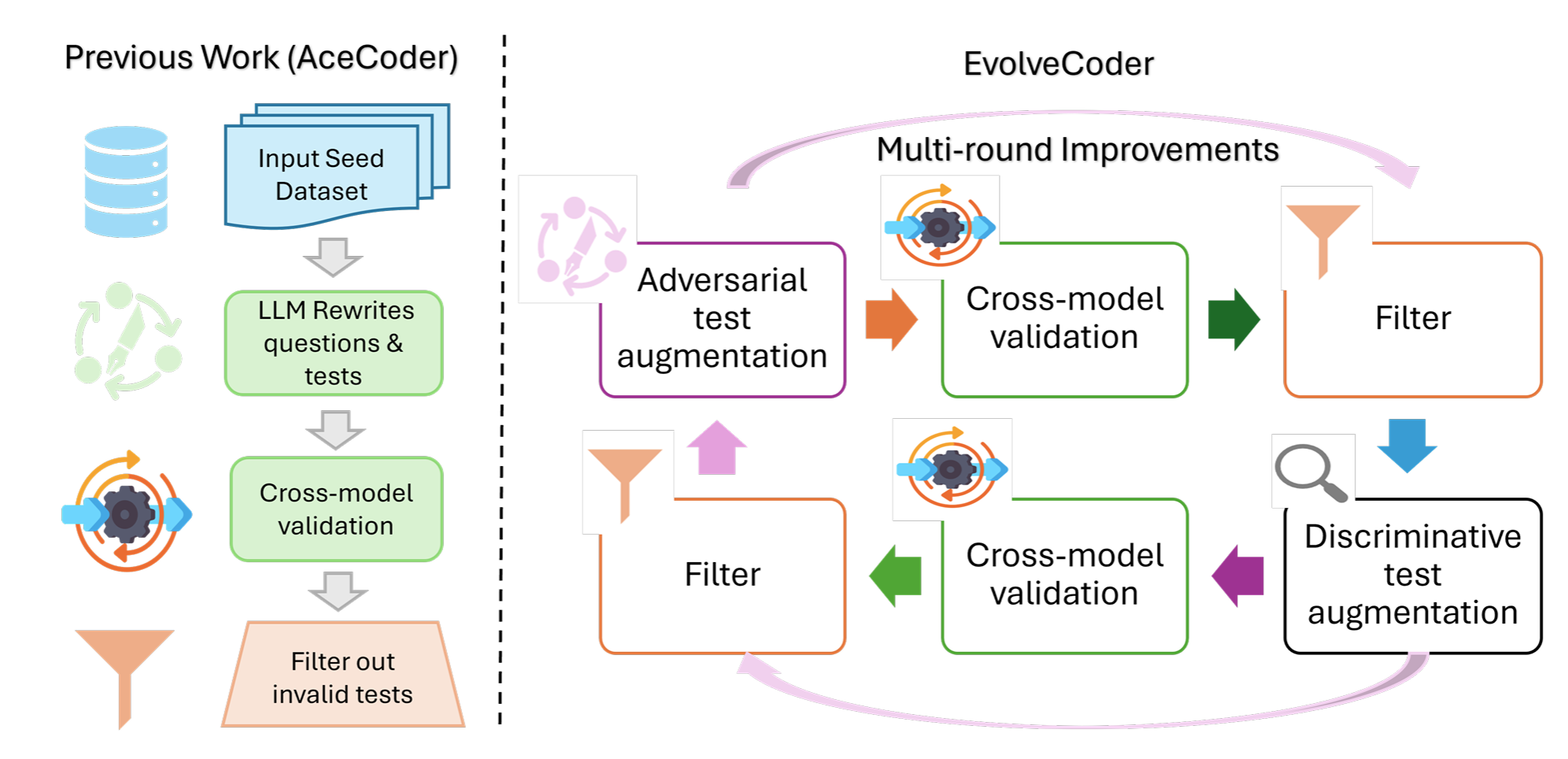
2025
- arXiv preprint, Sep 2025
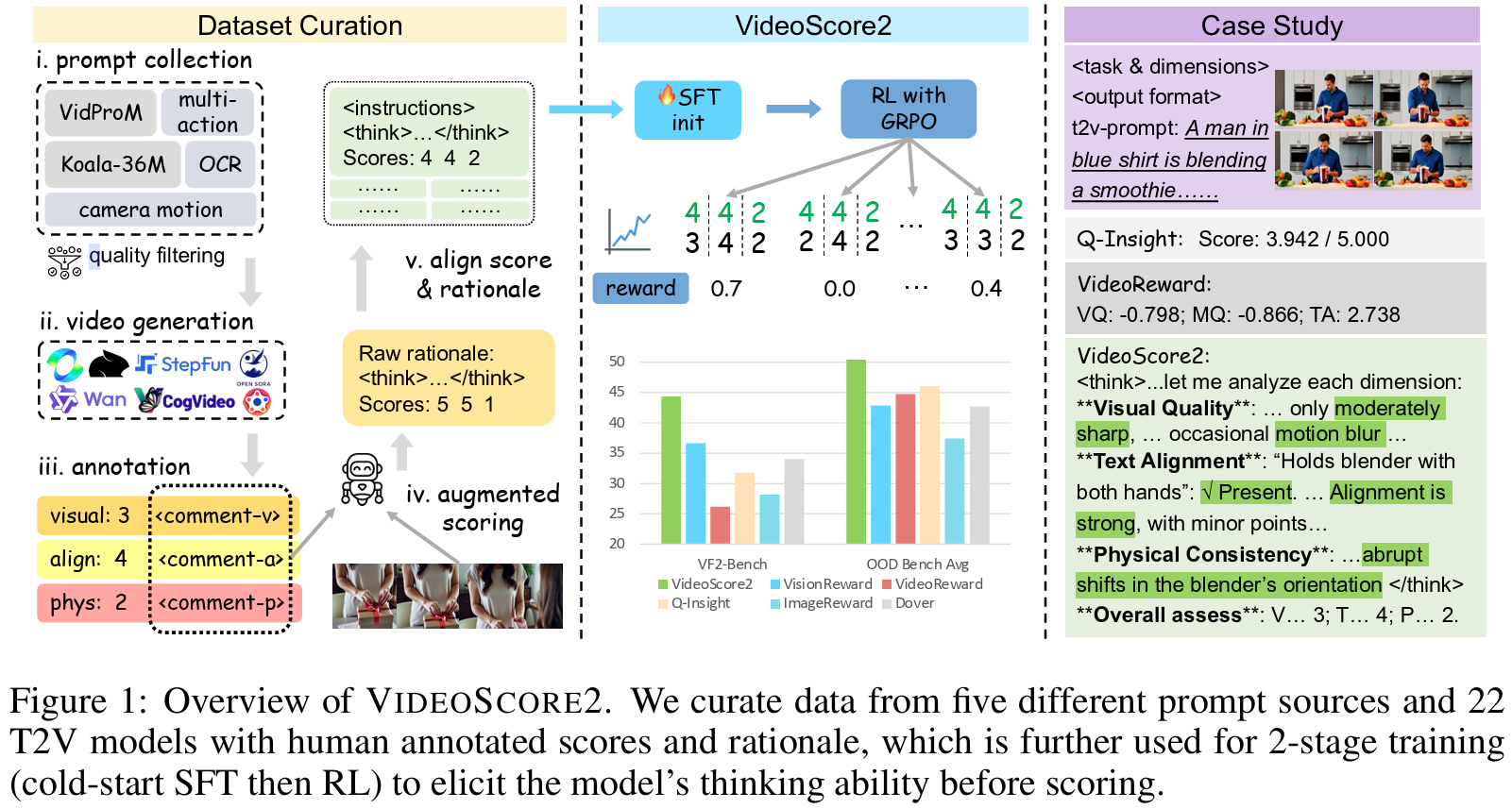
- ACL 2025In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jul 2025
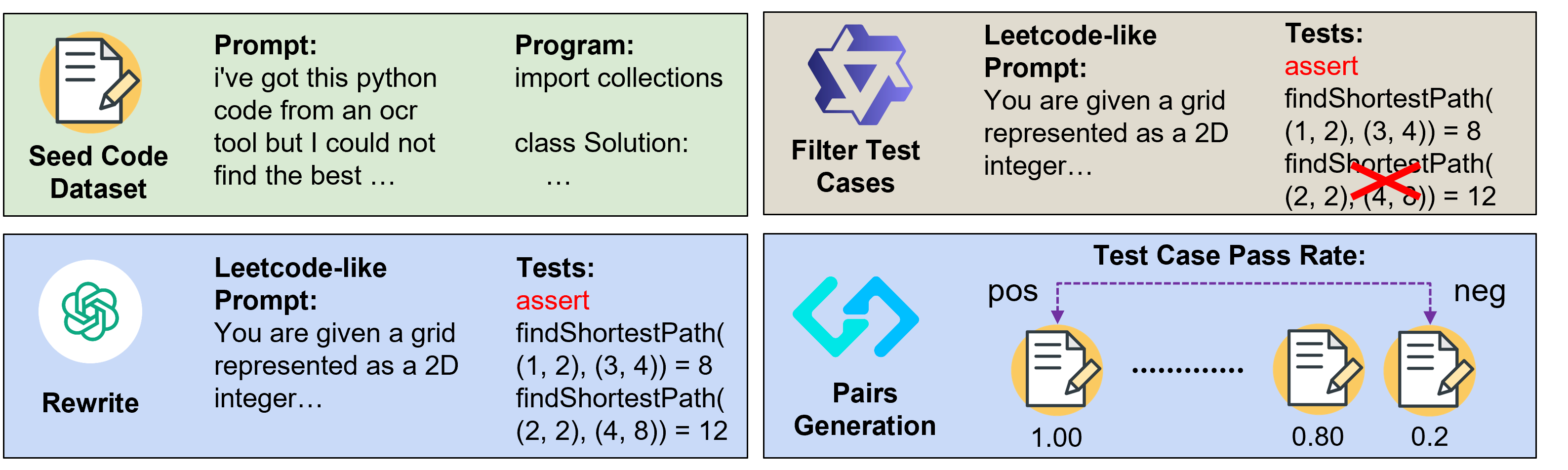
- In The Thirteenth International Conference on Learning Representations, Jul 2025
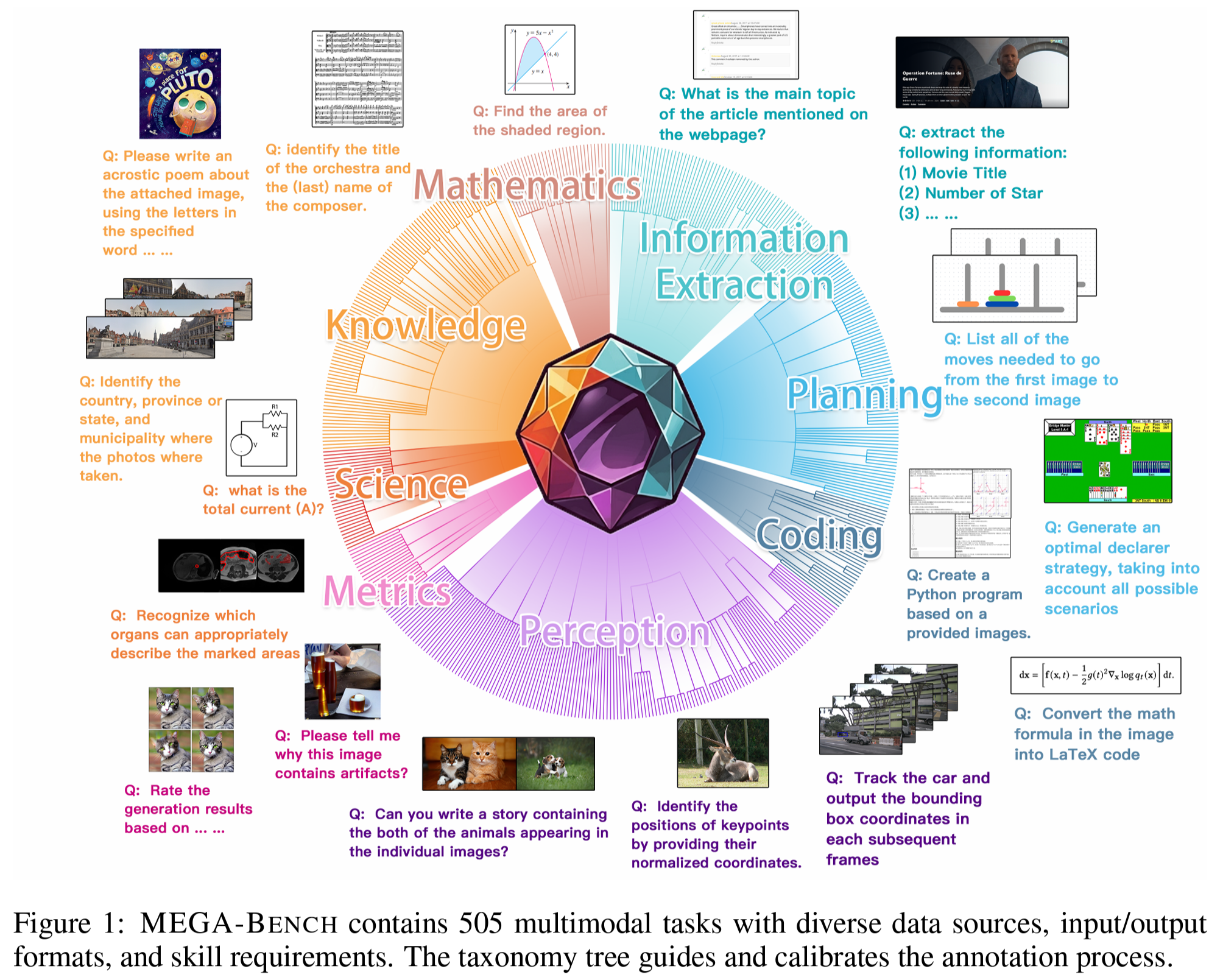
2024
- In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Nov 2024
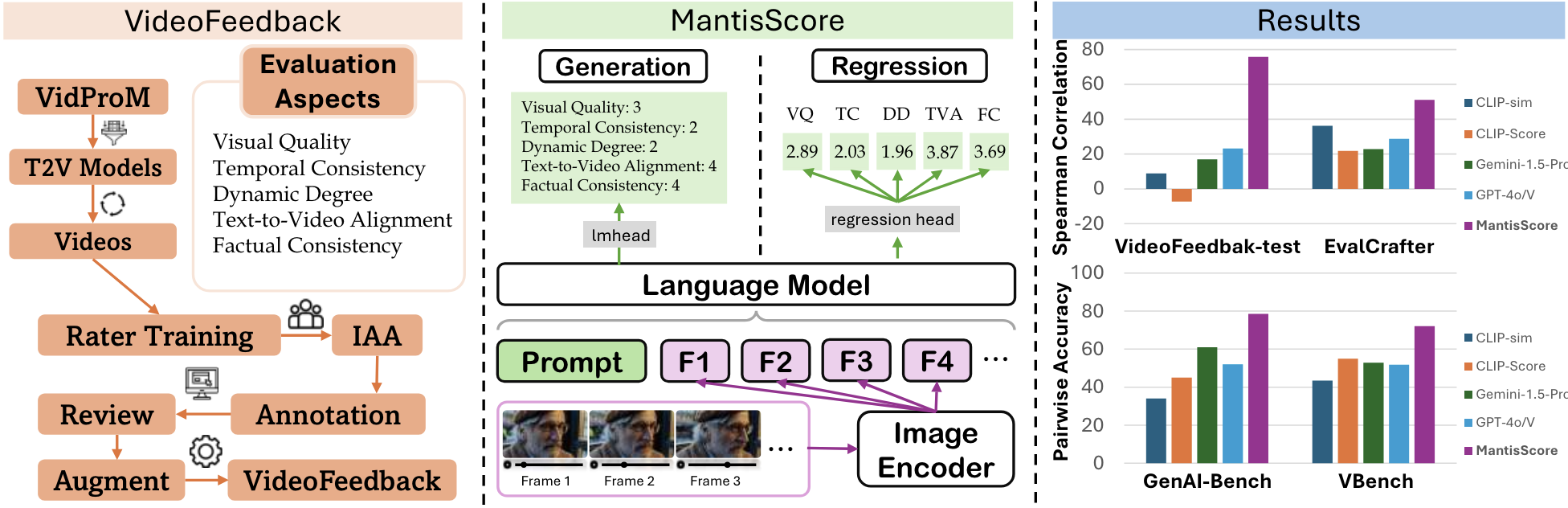
- In Advances in Neural Information Processing Systems 37 (NeurIPS 2024) Datasets and Benchmarks Track, Dec 2024

- In Advances in Neural Information Processing Systems 37 (NeurIPS 2024) Datasets and Benchmarks Track, Dec 2024
- Transactions on Machine Learning Research, Dec 2024Outstanding Paper Award at TMLR 2025 (1 / 1539 selected)
- In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024Best Paper Finalist and Oral at CVPR 2024 (24 / 11,532 selected)

- Transactions on Machine Learning Research, May 2024
2023
Experience
Full CVEducation
- 2023 - 2026
Ph.D. in Computer Science
- Advised by Prof. Wenhu Chen, TIGER-Lab
- Affiliate of the Vector Institute for AI
- 2019 - 2023
B.E. in Computer Science
- GPA 3.97 / 4.00
- Advised by Prof. Zhou Zhao

Research Experience
- Aug 2025 - Present
Research Intern
- Agentic reinforcement learning for tool use
- Contributing to post-training of Nemotron family of models

- Jun 2024 - Sep 2024
Research Intern
- Active learning with verbalized human feedback

- Feb 2024 - Sep 2025
Research Associate
- Worked on interleaved multi-image instruction tuning for multimodal language models

- Mar 2022 - Mar 2023
Research Intern
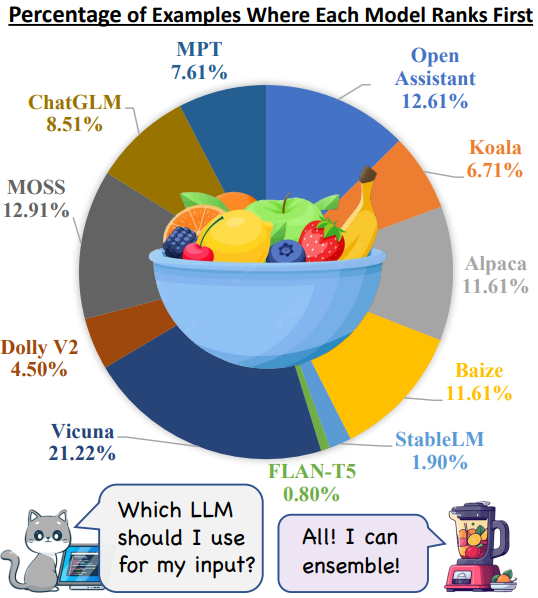
- Worked on methods for ensembling large language models with ranking and generation-based fusion
Impact
Full CV- 2023 - 2026
First / co-first works received broad online coverage, including MarkTechPost features on LLM-Blender, GenAI-Arena, OpenResearcher, and AceCoder.
- 2024 - 2026
MMMU has been cited by major multimodal model and benchmark works including Llama 3, LLaVA-OneVision, Cambrian-1, Kimi-VL, and Video-MME.
- 2023 - 2026
LLM-Blender has been cited by representative LLM systems and evaluation works including FrugalGPT, Prometheus 2, RewardBench, SimPO, and Mixture-of-Agents.
- 2024 - 2026
MANTIS has been cited by multimodal follow-up works including LLaVA-OneVision, LLaVA-NeXT-Interleave, Molmo / PixMo, InternVL3, and MMMU-Pro.
- 2025 - 2026
VerlTool has been cited by later agentic RL and tool-use works including DeepAgent, SkyRL, and AgentFlow.
- 2026
OpenResearcher's data has been adopted by NVIDIA's Nemotron family of models.
- 2025
AceCoder synthesized prompts were used in the coding RL data mixture of OLMo 3.
- 2024 - 2026
WildVision has been cited by follow-up multimodal evaluation and alignment works including LLaVA-Critic, InternVL3, InternVL3.5, and Mammoth-VL.