Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
No publications match this topic yet.
2026
- Yi Lu, Zhuofeng Li, Ping Nie, Haoxiang Zhang, Yuyu Zhang, Kai Zou, Wenhu Chen, Jimmy Lin, and 2 more authorsJun 2026
@article{lu2026drdci, title = {{Dr-DCI}: Scaling Direct Corpus Interaction via Dynamic Workspace Expansion}, author = {Lu, Yi and Li, Zhuofeng and Nie, Ping and Zhang, Haoxiang and Zhang, Yuyu and Zou, Kai and Chen, Wenhu and Lin, Jimmy and Jiang, Dongfu and Zhang, Yu}, year = {2026}, month = jun, journal = {arXiv preprint}, doi = {10.48550/arXiv.2606.14885}, topics = {Agentic RL & Tool Use | Systems & Infrastructure | Evaluation & Benchmarks}, selected = true, } - Zhangchen Xu, Junda Chen, Yue Huang, Dongfu Jiang, Jiefeng Chen, Hang Hua, Zijian Wu, Zheyuan Liu, and 11 more authorsJun 2026Core contributor
@article{autolab2026, title = {AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?}, author = {Xu, Zhangchen and Chen, Junda and Huang, Yue and Jiang, Dongfu and Chen, Jiefeng and Hua, Hang and Wu, Zijian and Liu, Zheyuan and He, Zexue and Li, Lichi and Diao, Shizhe and Pei, Jiaxin and Yoon, Jinsung and Zhang, Hao and Wang, Mengdi and Poovendran, Radha and Sra, Misha and Pentland, Alex and Chen, Zichen}, year = {2026}, month = jun, journal = {arXiv preprint}, doi = {10.48550/arXiv.2606.05080}, github = {autolabhq/autolab}, demo = {https://autolab.moe/live-lab}, twitter = {https://x.com/my_cat_can_code/status/2040290391300456583}, note = {Core contributor}, topics = {Agentic RL & Tool Use | Evaluation & Benchmarks | Systems & Infrastructure}, selected = true, } - Hui Chen, James Xu Zhao, Dongfu Jiang, Qianyun Guo, Jiefeng Chen, Yiwei Wang, Muhao Chen, See-Kiong Ng, and 2 more authorsMay 2026Best Paper @ ICML 2026 AI4Science Workshop
@article{chen2026fabscore, title = {{FABSCORE}: Fine-Grained Evaluation of Fabrications in Automated AI Research}, author = {Chen, Hui and Zhao, James Xu and Jiang, Dongfu and Guo, Qianyun and Chen, Jiefeng and Wang, Yiwei and Chen, Muhao and Ng, See-Kiong and Koh, Pang Wei and Hooi, Bryan}, year = {2026}, month = may, journal = {arXiv preprint}, github = {chchenhui/fabscore}, twitter = {https://x.com/DongfuJiang/status/2054280775164637204}, topics = {Evaluation & Benchmarks | Agentic RL & Tool Use}, selected = true, highlight = {Best Paper @ ICML 2026 AI4Science Workshop}, } - Zhuofeng Li, Haoxiang Zhang, Cong Wei, Pan Lu, Ping Nie, Yi Lu, Yuyang Bai, Shangbin Feng, and 11 more authorsMay 2026#1 Paper of the Day on Hugging Face Papers
@article{li2026beyondsemanticsimilarity, title = {Beyond Semantic Similarity ({DCI-Agent}): Rethinking Retrieval for Agentic Search via Direct Corpus Interaction}, author = {Li, Zhuofeng and Zhang, Haoxiang and Wei, Cong and Lu, Pan and Nie, Ping and Lu, Yi and Bai, Yuyang and Feng, Shangbin and Zhu, Hangxiao and Zhong, Ming and Zhang, Yuyu and Xie, Jianwen and Choi, Yejin and Zou, James and Han, Jiawei and Chen, Wenhu and Lin, Jimmy and Jiang, Dongfu and Zhang, Yu}, year = {2026}, month = may, journal = {arXiv preprint}, doi = {10.48550/arXiv.2605.05242}, github = {DCI-Agent/DCI-Agent-Lite}, dataset = {https://huggingface.co/datasets/DongfuJiang/AgenticSearchQA}, huggingface = {https://huggingface.co/papers/2605.05242}, topics = {Agentic RL & Tool Use | Systems & Infrastructure | Evaluation & Benchmarks}, selected = true, highlight = {{#}1 Paper of the Day on Hugging Face Papers}, } - Yuxuan Zhang, Penghui Du, Bo Li, Cong Wei, Junwen Miao, Huaisong Zhang, Songcheng Cai, Yubo Wang, and 6 more authorsMay 2026
@article{zhang2026rewardharness, title = {RewardHarness: Self-Evolving Agentic Post-Training}, author = {Zhang, Yuxuan and Du, Penghui and Li, Bo and Wei, Cong and Miao, Junwen and Zhang, Huaisong and Cai, Songcheng and Wang, Yubo and Jiang, Dongfu and Zhang, Yuyu and Nie, Ping and Chen, Wenhu and Yu, Changqian and Allen, Kelsey R.}, year = {2026}, month = may, journal = {arXiv preprint}, doi = {10.48550/arXiv.2605.08703}, topics = {LLM/VLM Post-Training | Agentic RL & Tool Use | Reward Models}, selected = false, } - Zhuofeng Li*, Yi Lu*, Dongfu Jiang, Haoxiang Zhang, Yuyang Bai, Chuan Li, Yu Wang, Shuiwang Ji, and 2 more authorsApr 2026
@article{li2026reviewgrounder, title = {ReviewGrounder: Improving Review Substantiveness with Rubric-Guided, Tool-Integrated Agents}, author = {Li, Zhuofeng and Lu, Yi and Jiang, Dongfu and Zhang, Haoxiang and Bai, Yuyang and Li, Chuan and Wang, Yu and Ji, Shuiwang and Xie, Jianwen and Zhang, Yu}, year = {2026}, month = apr, journal = {arXiv preprint}, doi = {10.48550/arXiv.2604.14261}, github = {EigenTom/ReviewGrounder}, topics = {Agentic RL & Tool Use | Evaluation & Benchmarks}, selected = false, num_co_first_author = {2}, } - Yuxuan Zhang, Yubo Wang, Yipeng Zhu, Penghui Du, Junwen Miao, Xuan Lu, Wendong Xu, Yunzhuo Hao, and 13 more authorsApr 2026
@article{zhang2026clawbench, title = {ClawBench: Can AI Agents Complete Everyday Online Tasks?}, author = {Zhang, Yuxuan and Wang, Yubo and Zhu, Yipeng and Du, Penghui and Miao, Junwen and Lu, Xuan and Xu, Wendong and Hao, Yunzhuo and Cai, Songcheng and Wang, Xiaochen and Zhang, Huaisong and Wu, Xian and Lu, Yi and Lei, Minyi and Zou, Kai and Yin, Huifeng and Nie, Ping and Chen, Liang and Jiang, Dongfu and Chen, Wenhu and Allen, Kelsey R.}, year = {2026}, month = apr, journal = {arXiv preprint}, doi = {10.48550/arXiv.2604.08523}, twitter = {https://x.com/DongfuJiang/status/2043625442578711012}, topics = {Evaluation & Benchmarks | Agentic RL & Tool Use}, selected = false, } - Yuxuan Zhang, EunJeong Hwang, Huaisong Zhang, Penghui Du, Yiming Jia, Dongfu Jiang, Xuan He, Shenhui Zhang, and 3 more authorsApr 2026
@article{zhang2026watchbeforeyouanswer, title = {Watch Before You Answer: Learning from Visually Grounded Post-Training}, author = {Zhang, Yuxuan and Hwang, EunJeong and Zhang, Huaisong and Du, Penghui and Jia, Yiming and Jiang, Dongfu and He, Xuan and Zhang, Shenhui and Nie, Ping and West, Peter and Allen, Kelsey R.}, year = {2026}, month = apr, journal = {arXiv preprint}, doi = {10.48550/arXiv.2604.05117}, twitter = {https://x.com/DongfuJiang/status/2042002570793898078}, topics = {LLM/VLM Post-Training | Multimodal Reasoning}, selected = false, } - Zhuolin Yang, Zihan Liu, Yang Chen, Wenliang Dai, Boxin Wang, Sheng-Chieh Lin, Chankyu Lee, Yangyi Chen, and 9 more authorsMar 2026
We introduce Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters that delivers best-in-class reasoning and strong agentic capabilities. Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeekV3.2-Speciale-671B-A37B, to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20x fewer parameters. In contrast to Nemotron-Cascade 1, the key technical advancements are as follows. After SFT on a meticulously curated dataset, we substantially expand Cascade RL to cover a much broader spectrum of reasoning and agentic domains. Furthermore, we introduce multi-domain on-policy distillation from the strongest intermediate teacher models for each domain throughout the Cascade RL process, allowing us to efficiently recover benchmark regressions and sustain strong performance gains along the way. We release the collection of model checkpoint and training data.
@article{yang2026nemotroncascade2, title = {Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation}, author = {Yang, Zhuolin and Liu, Zihan and Chen, Yang and Dai, Wenliang and Wang, Boxin and Lin, Sheng-Chieh and Lee, Chankyu and Chen, Yangyi and Jiang, Dongfu and He, Jiafan and Pi, Renjie and Lam, Grace and Lee, Nayeon and Bukharin, Alexander and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei}, year = {2026}, month = mar, journal = {Industrial technical report}, doi = {10.48550/arXiv.2603.19220}, huggingface = {https://huggingface.co/collections/nvidia/nemotron-cascade-2}, topics = {LLM/VLM Post-Training | Agentic RL & Tool Use}, selected = true, }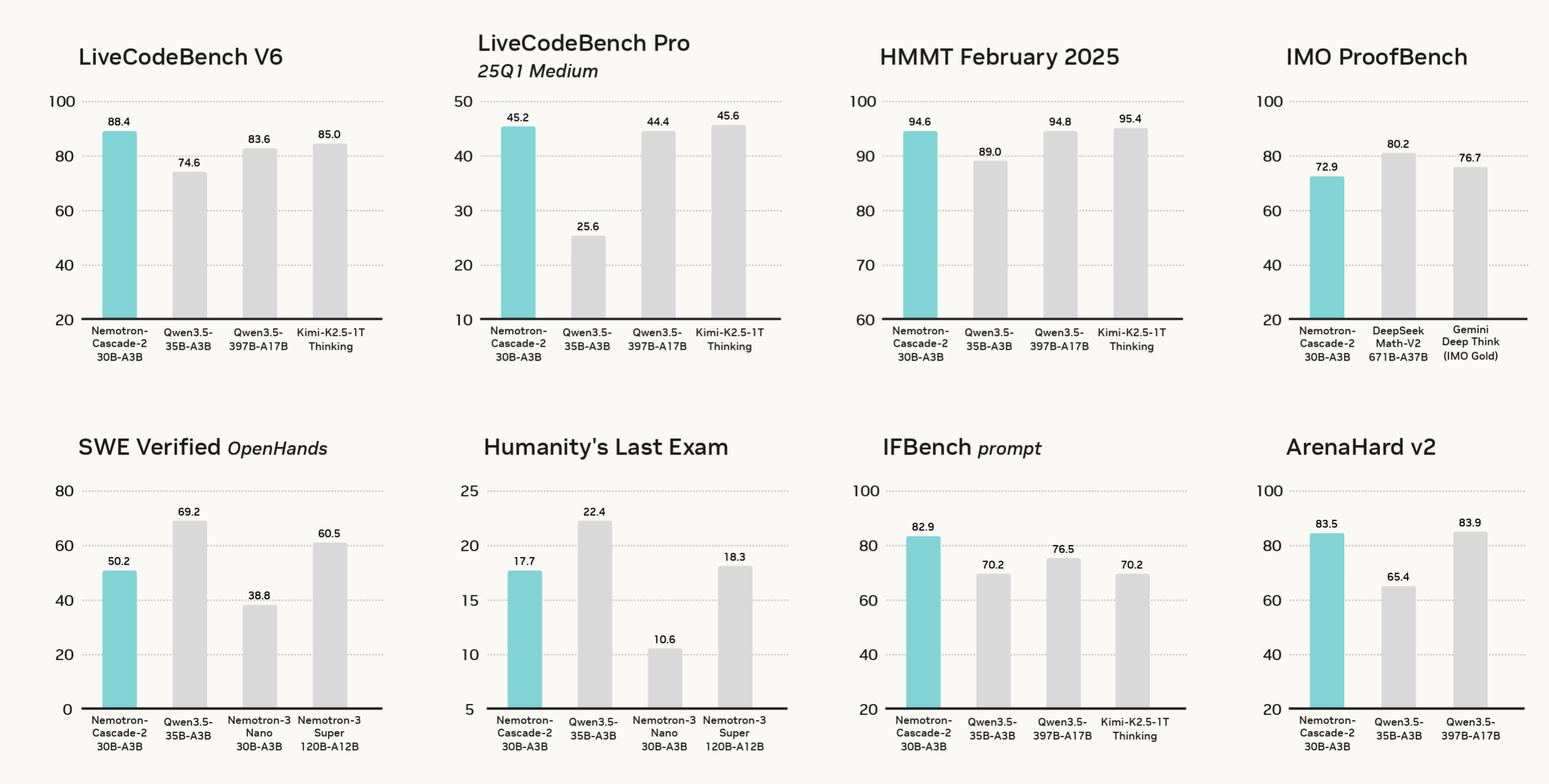
- Chi Ruan, Dongfu Jiang, Huaye Zeng, Ping Nie, and Wenhu ChenMar 2026
Reinforcement learning with verifiable rewards (RLVR) is a promising approach for improving code generation in large language models, but its effectiveness is limited by weak and static verification signals in existing coding RL datasets. In this paper, we propose a solution-conditioned and adversarial verification framework that iteratively refines test cases based on the execution behaviors of candidate solutions, with the goal of increasing difficulty, improving discriminative power, and reducing redundancy. Based on this framework, we introduce EvolveCoder-22k, a large-scale coding reinforcement learning dataset constructed through multiple rounds of adversarial test case evolution. Empirical analysis shows that iterative refinement substantially strengthens verification, with pass@1 decreasing from 43.80 to 31.22. Reinforcement learning on EvolveCoder-22k yields stable optimization and consistent performance gains, improving Qwen3-4B by an average of 4.2 points across four downstream benchmarks and outperforming strong 4B-scale baselines. Our results highlight the importance of adversarial, solution-conditioned verification for effective and scalable reinforcement learning in code generation.
@article{ruan2026evolvecoder, title = {EvolveCoder: Evolving Test Cases via Adversarial Verification for Code Reinforcement Learning}, author = {Ruan, Chi and Jiang, Dongfu and Zeng, Huaye and Nie, Ping and Chen, Wenhu}, year = {2026}, month = mar, journal = {arXiv preprint}, doi = {10.48550/arXiv.2603.12698}, topics = {LLM/VLM Post-Training | Coding LLMs | Data Synthesis | Reward Models}, selected = false, num_co_first_author = {1}, }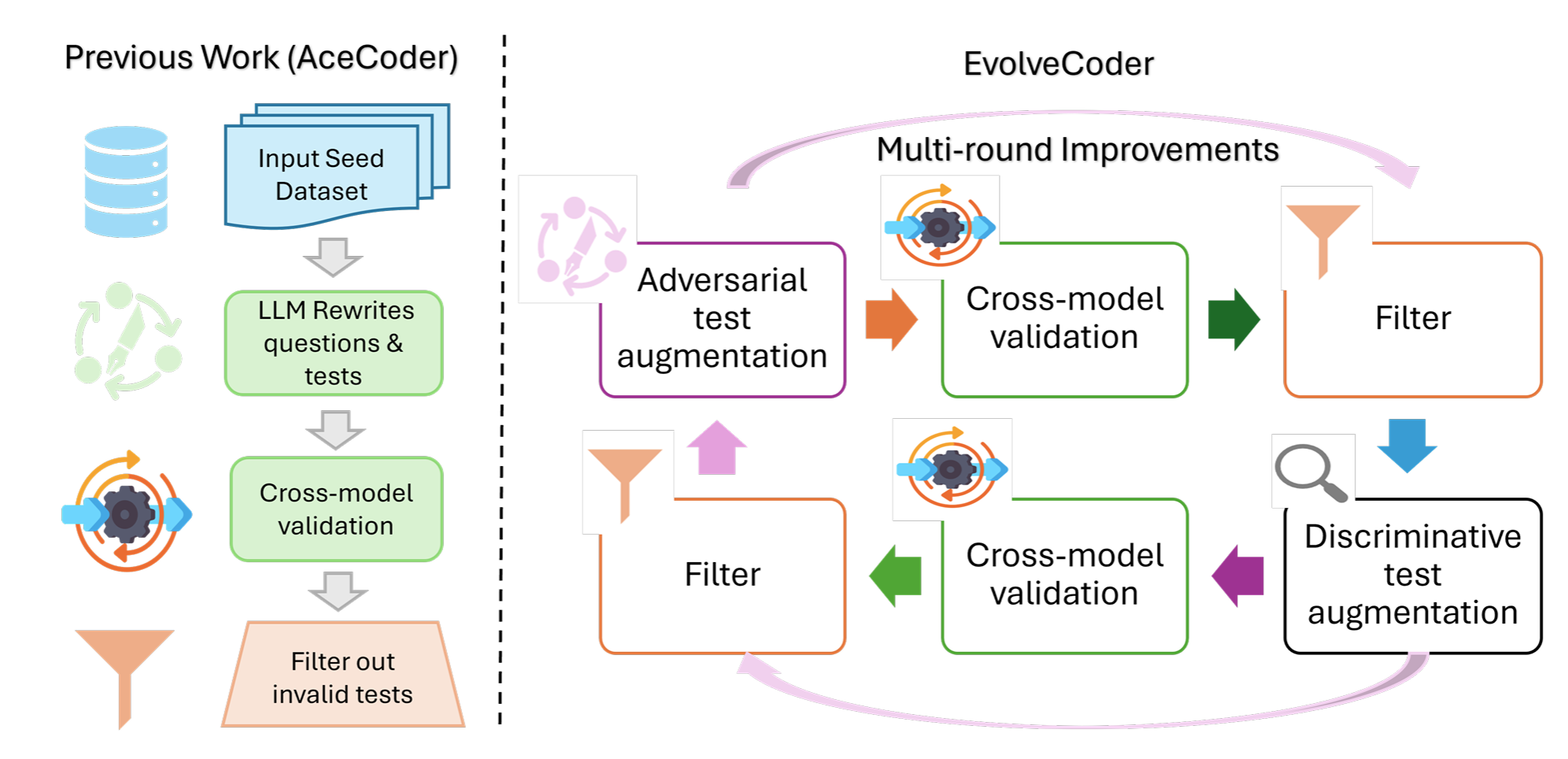
- Core ContributorApr 2026
@article{jiang2026nemotron3super, title = {Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning}, author = {Contributor, Core}, year = {2026}, month = apr, journal = {Industrial technical report}, doi = {10.48550/arXiv.2604.12374}, topics = {LLM/VLM Post-Training | Agentic RL & Tool Use}, selected = true, }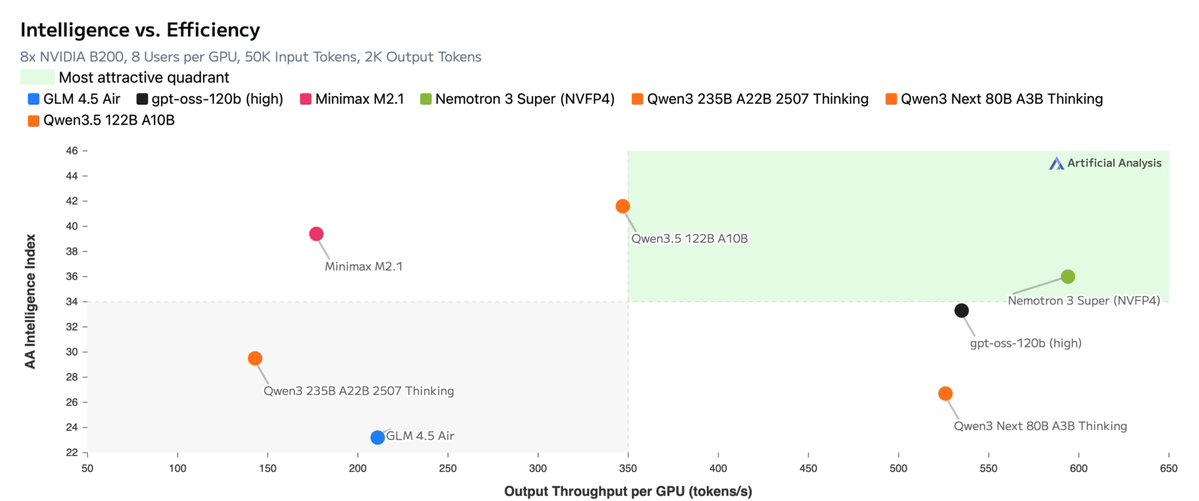
- NVIDIA: Aaron Blakeman et al., and Dongfu JiangJun 2026
@article{blakeman2026nemotron3ultra, title = {Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning}, author = {{NVIDIA: Aaron Blakeman et al.} and Jiang, Dongfu}, year = {2026}, month = jun, journal = {Industrial technical report}, doi = {10.48550/arXiv.2606.15007}, topics = {LLM/VLM Post-Training | Agentic RL & Tool Use}, selected = true, } - NVIDIA: Aditi et al., and Dongfu JiangJun 2026
@article{agarwal2026cosmos3, title = {Cosmos 3: Omnimodal World Models for Physical AI}, author = {{NVIDIA: Aditi et al.} and Jiang, Dongfu}, year = {2026}, month = jun, journal = {Industrial technical report}, doi = {10.48550/arXiv.2606.02800}, topics = {Multimodal Reasoning | Systems & Infrastructure}, selected = true, } - Zhuofeng Li*, Dongfu Jiang*, Xueguang Ma, Haoxiang Zhang, Ping Nie, Yuyu Zhang, Kai Zou, Jianwen Xie, and 2 more authorsMar 2026
@article{li2026openresearcher, title = {OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis}, author = {Li, Zhuofeng and Jiang, Dongfu and Ma, Xueguang and Zhang, Haoxiang and Nie, Ping and Zhang, Yuyu and Zou, Kai and Xie, Jianwen and Zhang, Yu and Chen, Wenhu}, year = {2026}, month = mar, journal = {arXiv preprint}, doi = {10.48550/arXiv.2603.20278}, github = {TIGER-AI-Lab/OpenResearcher}, huggingface = {https://huggingface.co/collections/TIGER-Lab/openresearcher}, dataset = {https://huggingface.co/datasets/OpenResearcher/OpenResearcher-Dataset}, model = {https://huggingface.co/OpenResearcher/OpenResearcher-30B-A3B}, demo = {https://huggingface.co/spaces/OpenResearcher/OpenResearcher}, video = {https://x.com/zhuofengli96475/status/2021682952074097086}, twitter = {https://x.com/DongfuJiang/status/2020946549422031040}, topics = {Data Synthesis | Agentic RL & Tool Use}, selected = true, num_co_first_author = {2}, }
- Xuan He*, Dongfu Jiang*, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, and 16 more authorsSep 2026
Recent advances in text-to-video generation have produced increasingly realistic and diverse content, yet evaluating such videos remains a fundamental challenge due to their multi-faceted nature encompassing visual quality, semantic alignment, and physical consistency. Existing evaluators and reward models are limited to single opaque scores, lack interpretability, or provide only coarse analysis, making them insufficient for capturing the comprehensive nature of video quality assessment. We present VideoScore2, a multi-dimensional, interpretable, and human-aligned framework that explicitly evaluates visual quality, text-to-video alignment, and physical/common-sense consistency while producing detailed chain-of-thought rationales. Our model is trained on a large-scale dataset VideoFeedback2 containing 27,168 human-annotated videos with both scores and reasoning traces across three dimensions, using a two-stage pipeline of supervised fine-tuning followed by reinforcement learning with Group Relative Policy Optimization (GRPO) to enhance analytical robustness. Extensive experiments demonstrate that VideoScore2 achieves superior performance with 44.35 (+5.94) accuracy on our in-domain benchmark VideoScore-Bench-v2 and 50.37 (+4.32) average performance across four out-of-domain benchmarks (VideoGenReward-Bench, VideoPhy2, etc), while providing interpretable assessments that bridge the gap between evaluation and controllable generation through effective reward modeling for Best-of-N sampling. Project Page: this https URL
@article{He2025VideoScore2TB, title = {VideoScore2: Think before You Score in Generative Video Evaluation}, author = {He, Xuan and Jiang, Dongfu and Nie, Ping and Liu, Minghao and Jiang, Zhengxuan and Su, Mingyi and Ma, Wentao and Lin, Junru and Ye, Chun and Lu, Yi and Wu, Keming and Schneider, Benjamin and Do, Quy Duc and Li, Zhuofeng and Jia, Yiming and Zhang, Yuxuan and Cheng, Guo and Wang, Haozhe and Zhou, Wangchunshu and Lin, Qunshu and Zhang, Yuanxing and Zhang, Ge and Huang, Wenhao and Chen, Wenhu}, year = {2026}, month = sep, journal = {Transactions on Machine Learning Research}, github = {TIGER-AI-Lab/VideoScore2}, huggingface = {https://huggingface.co/collections/TIGER-Lab/videoscore2-68dbe2618ceec197d39fe19d}, twitter = {https://x.com/WenhuChen/status/1973546309106720908}, topics = {LLM/VLM Post-Training | Evaluation & Benchmarks | Multimodal Reasoning | Reward Models}, selected = false, num_co_first_author = {2}, }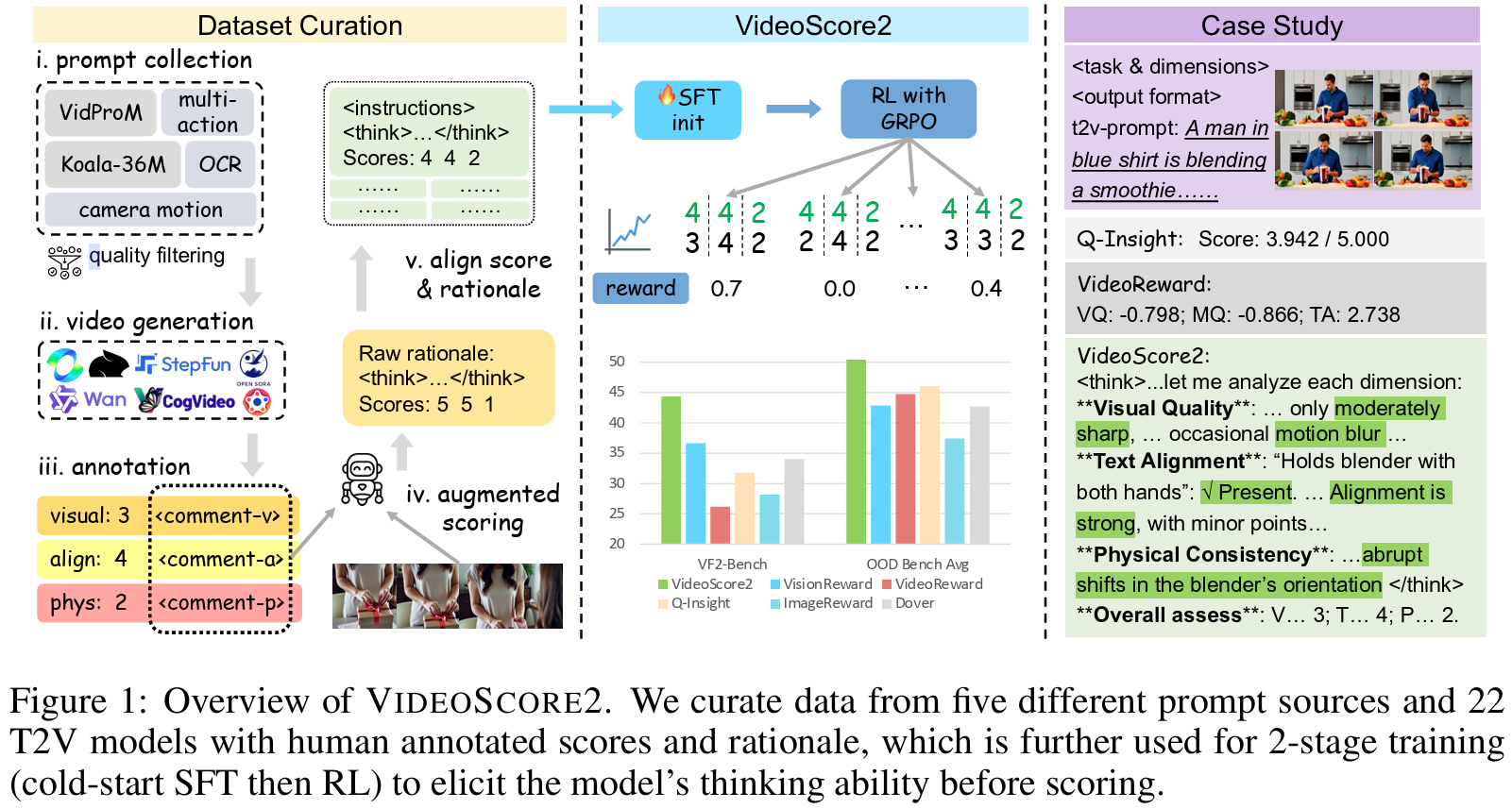
- Chi Ruan, Dongfu Jiang, Yubo Wang, and Wenhu ChenSep 2026
Reinforcement Learning (RL) has emerged as a popular training paradigm, particularly when paired with reasoning models. While effective, it primarily focuses on generating responses and lacks mechanisms to explicitly foster critique or reflection. Several recent studies, like Critique-Fine-Tuning (CFT) and Critique-Guided-Distillation (CGD) have shown the benefits of explicitly teaching LLMs how to critique. Motivated by them, we propose Critique Reinforcement Learning (CRL), where the model is tasked with generating a critique for a given (question, solution) pair. The reward is determined solely by whether the final judgment label c∈𝚃𝚛𝚞𝚎,𝙵𝚊𝚕𝚜𝚎 of the generated critique aligns with the ground-truth judgment c∗. Building on this point, we introduce \textscCritique-Coder, which is trained on a hybrid of RL and CRL by substituting 20% of the standard RL data with CRL data. We fine-tune multiple models (\textscCritique-Coder) and evaluate them on different benchmarks to show their advantages over RL-only models. We show that \textscCritique-Coder consistently outperforms RL-only baselines on all the evaluated benchmarks. Notably, our \textscCritique-Coder-8B can reach over 60% on LiveCodeBench (v5), outperforming other reasoning models like DeepCoder-14B and GPT-o1. Beyond code generation, \textscCritique-Coder also demonstrates enhanced general reasoning abilities, as evidenced by its better performance on logic reasoning tasks from the BBEH dataset. This indicates that the application of CRL on coding datasets enhances general reasoning and critique abilities, which are transferable across a broad range of tasks. Hence, we believe that CRL works as a great complement to standard RL for LLM reasoning.
@inproceedings{Ruan2025CritiqueCoderEC, title = {Critique-Coder: Enhancing Coder Models by Critique Reinforcement Learning}, author = {Ruan, Chi and Jiang, Dongfu and Wang, Yubo and Chen, Wenhu}, year = {2026}, booktitle = {The Fourteenth International Conference on Learning Representations}, github = {TIGER-AI-Lab/Critique-Coder}, huggingface = {https://huggingface.co/collections/TIGER-Lab/critique-coder-68dbdcdf09dbf87ed11822e4}, dataset = {https://huggingface.co/datasets/TIGER-Lab/rStar-Critique-Data}, twitter = {https://x.com/WenhuChen/status/1973149191309258795}, topics = {LLM/VLM Post-Training | Coding LLMs}, selected = false, num_co_first_author = {1}, }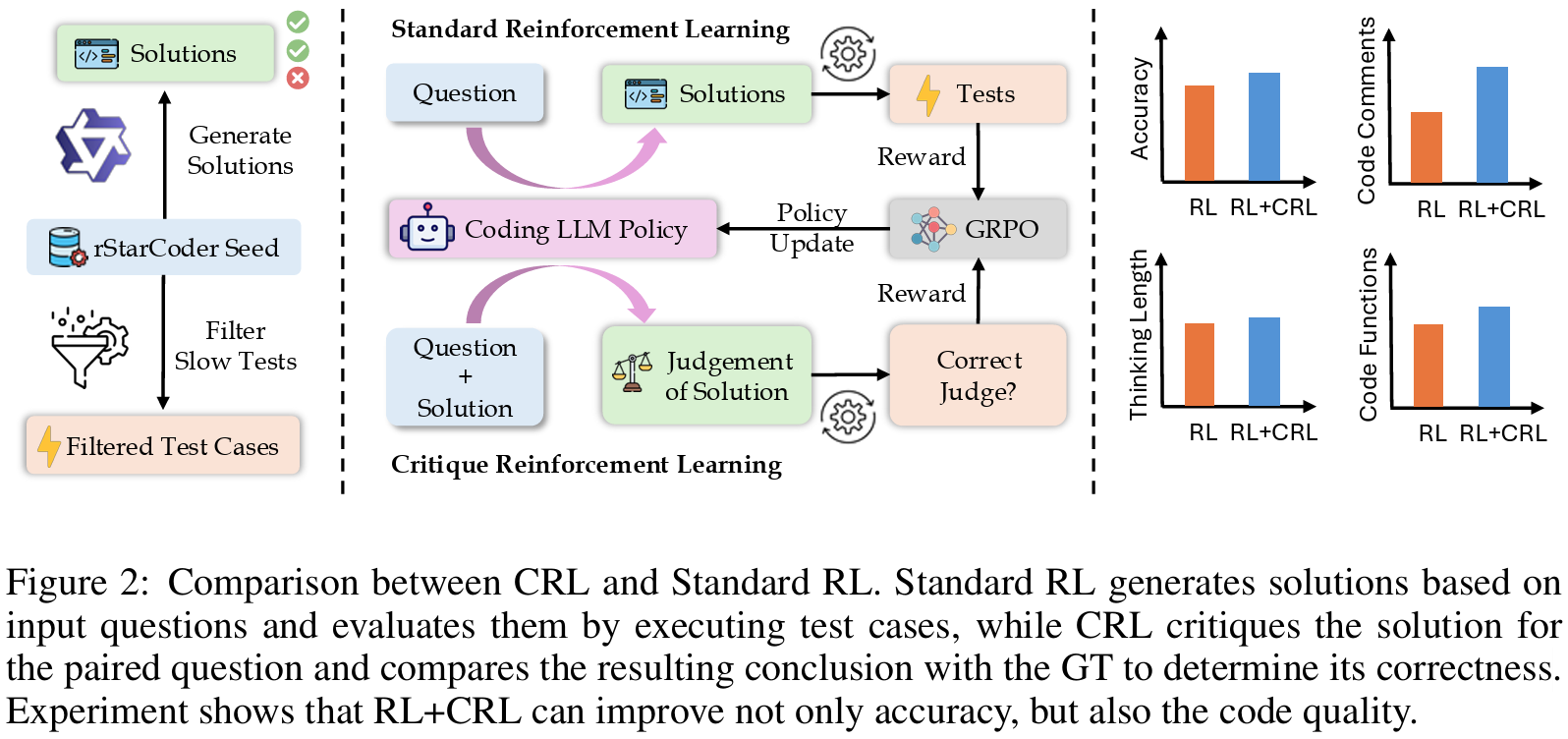
- Dongfu Jiang*, Yi Lu*, Zhuofeng Li*, Zhiheng Lyu*, Ping Nie, Haozhe Wang, Alex Su, Hui Chen, and 4 more authorsFeb 2026Best Paper @ SPOT @ ICLR 2026
Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated success in enhancing LLM reasoning capabilities, but remains limited to single-turn interactions without tool integration. While recent Agentic Reinforcement Learning with Tool use (ARLT) approaches have emerged to address multi-turn tool interactions, existing works develop task-specific codebases that suffer from fragmentation, synchronous execution bottlenecks, and limited extensibility across domains. These inefficiencies hinder broader community adoption and algorithmic innovation. We introduce VerlTool, a unified and modular framework that addresses these limitations through systematic design principles. VerlTool provides four key contributions: (1) upstream alignment with VeRL ensuring compatibility and simplified maintenance, (2) unified tool management via standardized APIs supporting diverse modalities including code execution, search, SQL databases, and vision processing, (3) asynchronous rollout execution achieving near 2x speedup by eliminating synchronization bottlenecks, and (4) comprehensive evaluation demonstrating competitive performance across 6 ARLT domains. Our framework formalizes ARLT as multi-turn trajectories with multi-modal observation tokens (text/image/video), extending beyond single-turn RLVR paradigms. We train and evaluate models on mathematical reasoning, knowledge QA, SQL generation, visual reasoning, web search, and software engineering tasks, achieving results comparable to specialized systems while providing unified training infrastructure. The modular plugin architecture enables rapid tool integration requiring only lightweight Python definitions, significantly reducing development overhead and providing a scalable foundation for tool-augmented RL research. Our code is open-sourced at this https URL.
@article{Jiang2025VerlToolTH, title = {VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use}, author = {Jiang, Dongfu and Lu, Yi and Li, Zhuofeng and Lyu, Zhiheng and Nie, Ping and Wang, Haozhe and Su, Alex and Chen, Hui and Zou, Kai and Du, Chao and Pang, Tianyu and Chen, Wenhu}, year = {2026}, month = feb, journal = {Transactions on Machine Learning Research}, github = {TIGER-AI-Lab/verl-tool}, twitter = {https://x.com/DongfuJiang/status/1963160374209134608}, topics = {Agentic RL & Tool Use | Systems & Infrastructure}, selected = true, num_co_first_author = {4}, highlight = {Best Paper @ SPOT @ ICLR 2026}, }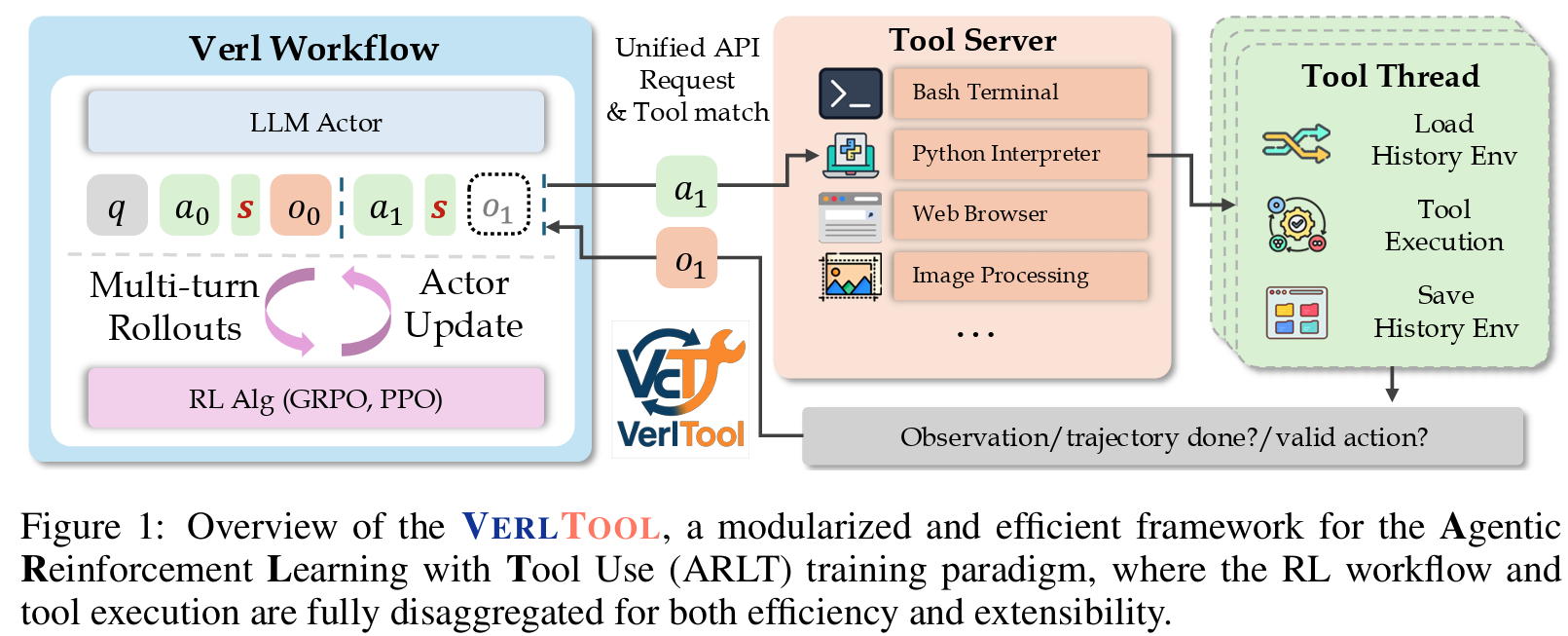
2025
- Jialin Yang*, Dongfu Jiang*, Lipeng He, Sherman Siu, Yuxuan Zhang, Disen Liao, Zhuofeng Li, Huaye Zeng, and 12 more authorsMay 2025Journal to Conference Certificate at TMLR 2025
As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs’ capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps: even state-of-the-art models like o1-mini achieve only a 75.58 average score, with open-source alternatives lagging by approximately 10 points. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
@article{yang2025structeval, title = {StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs}, author = {Yang, Jialin and Jiang, Dongfu and He, Lipeng and Siu, Sherman and Zhang, Yuxuan and Liao, Disen and Li, Zhuofeng and Zeng, Huaye and Jia, Yiming and Wang, Haozhe and Schneider, Benjamin and Ruan, Chi and Ma, Wentao and Lyu, Zhiheng and Wang, Yifei and Lu, Yi and Do, Quy Duc and Jiang, Ziyan and Nie, Ping and Chen, Wenhu}, journal = {Transactions on Machine Learning Research}, year = {2025}, month = may, doi = {10.48550/arXiv.2505.20139}, url = {https://openreview.net/forum?id=buDwV7LUA7}, topics = {Evaluation & Benchmarks}, github = {TIGER-AI-Lab/StructEval}, selected = false, num_co_first_author = {2}, highlight = {Journal to Conference Certificate at TMLR 2025}, }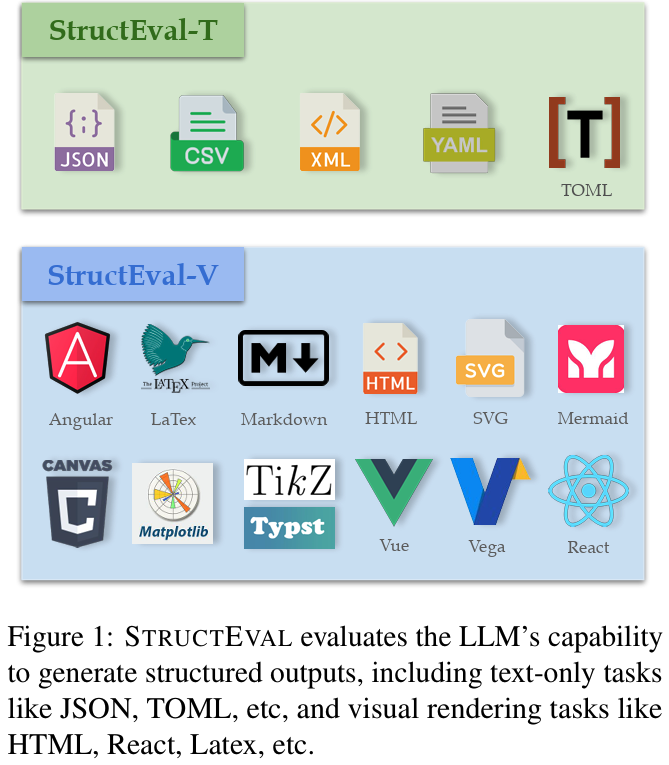
- May 2025
Long-video understanding has emerged as a crucial capability in real-world applications such as video surveillance, meeting summarization, educational lecture analysis, and sports broadcasting. However, it remains computationally prohibitive for VideoLLMs, primarily due to two bottlenecks: 1) sequential video decoding, the process of converting the raw bit stream to RGB frames can take up to a minute for hour-long video inputs, and 2) costly prefilling of up to several million tokens for LLM inference, resulting in high latency and memory use. To address these challenges, we propose QuickVideo, a system-algorithm co-design that substantially accelerates long-video understanding to support real-time downstream applications. It comprises three key innovations: QuickDecoder, a parallelized CPU-based video decoder that achieves 2-3 times speedup by splitting videos into keyframe-aligned intervals processed concurrently; QuickPrefill, a memory-efficient prefilling method using KV-cache pruning to support more frames with less GPU memory; and an overlapping scheme that overlaps CPU video decoding with GPU inference. Together, these components reduce inference time by about a minute on long video inputs, enabling scalable, high-quality video understanding even on limited hardware. Experiments show that QuickVideo generalizes across durations and sampling rates, making long video processing feasible in practice.
@article{schneider2025quickvideo, title = {QuickVideo: Real-Time Long Video Understanding with System Algorithm Co-Design}, author = {Schneider, Benjamin and Jiang, Dongfu and Du, Chao and Pang, Tianyu and Chen, Wenhu}, journal = {Transactions on Machine Learning Research}, year = {2025}, month = may, url = {https://openreview.net/forum?id=Rpcxgzcsuc}, topics = {Systems & Infrastructure}, github = {TIGER-AI-Lab/QuickVideo}, selected = false, num_co_first_author = {2}, }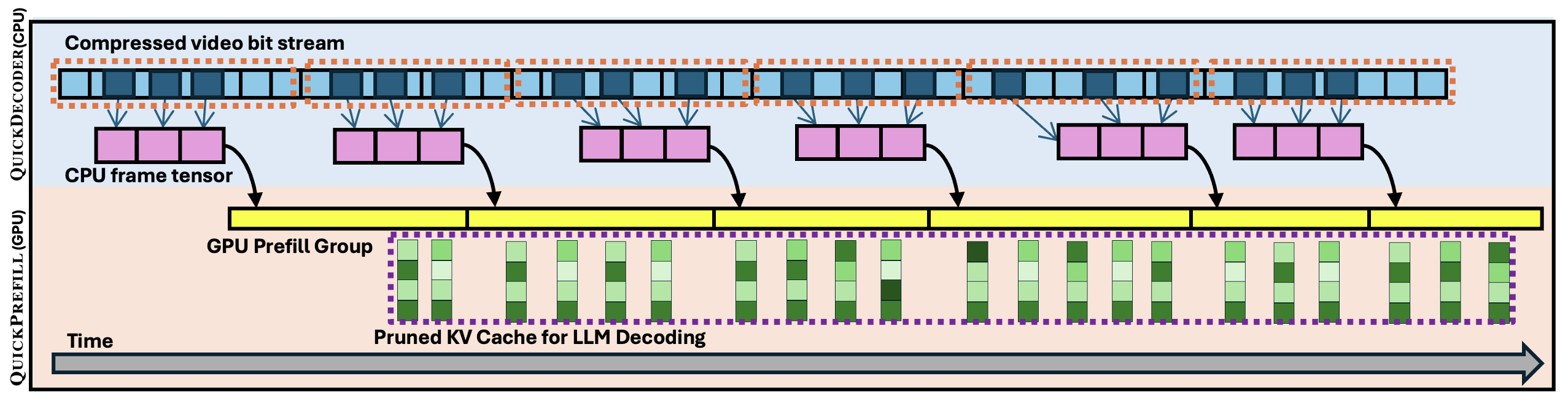
- ACL 2025Huaye Zeng*, Dongfu Jiang*, Haozhe Wang, Ping Nie, Xiaotong Chen, and Wenhu ChenJul 2025
Most progress in recent coder models has been driven by supervised fine-tuning (SFT), while the potential of reinforcement learning (RL) remains largely unexplored, primarily due to the lack of reliable reward data/model in the code domain. In this paper, we address this challenge by leveraging automated large-scale test-case synthesis to enhance code model training. Specifically, we design a pipeline that generates extensive (question, test-cases) pairs from existing code data. Using these test cases, we construct preference pairs based on pass rates over sampled programs to train reward models with Bradley-Terry loss. It shows an average of 10-point improvement for Llama-3.1-8B-Ins and 5-point improvement for Qwen2.5-Coder-7B-Ins through best-of-32 sampling, making the 7B model on par with 236B DeepSeek-V2.5. Furthermore, we conduct reinforcement learning with both reward models and test-case pass rewards, leading to consistent improvements across HumanEval, MBPP, BigCodeBench, and LiveCodeBench (V4). Notably, we follow the R1-style training to start from Qwen2.5-Coder-base directly and show that our RL training can improve model on HumanEval-plus by over 25% and MBPP-plus by 6% for merely 80 optimization steps. We believe our results highlight the huge potential of reinforcement learning in coder models.
@inproceedings{Zeng2025ACECODERAC, title = {ACECODER: Acing Coder RL via Automated Test-Case Synthesis}, author = {Zeng, Huaye and Jiang, Dongfu and Wang, Haozhe and Nie, Ping and Chen, Xiaotong and Chen, Wenhu}, booktitle = {Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = jul, year = {2025}, address = {Vienna, Austria}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.acl-long.327/}, doi = {10.18653/v1/2025.acl-long.327}, github = {TIGER-AI-Lab/AceCoder}, huggingface = {https://huggingface.co/collections/TIGER-Lab/acecoder-67a16011a6c7d65cad529eba}, twitter = {https://x.com/DongfuJiang/status/1886828310841204859}, topics = {LLM/VLM Post-Training | Coding LLMs | Data Synthesis | Reward Models}, selected = false, num_co_first_author = {2}, }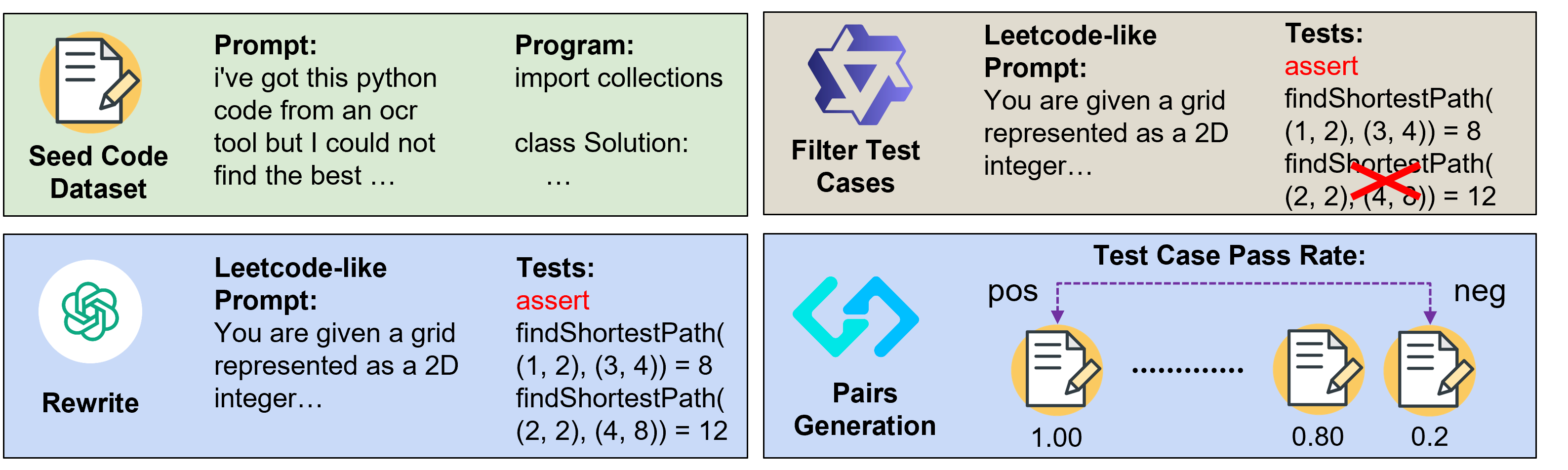
- Jiacheng Chen*, Tianhao Liang*, Sherman Siu*, Zhengqing Wang, Kai Wang, Yubo Wang, Yuansheng Ni, Ziyan Jiang, and 8 more authorsJul 2025
We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
@inproceedings{Chen2024MEGABenchSM, title = {{MEGA}-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks}, author = {Chen, Jiacheng and Liang, Tianhao and Siu, Sherman and Wang, Zhengqing and Wang, Kai and Wang, Yubo and Ni, Yuansheng and Jiang, Ziyan and Zhu, Wang and Lyu, Bohan and Jiang, Dongfu and He, Xuan and Liu, Yuan and Hu, Hexiang and Yue, Xiang and Chen, Wenhu}, booktitle = {The Thirteenth International Conference on Learning Representations}, year = {2025}, url = {https://proceedings.iclr.cc/paper_files/paper/2025/hash/461f1fd5f92e5ca95764a88304dc39f7-Abstract-Conference.html}, address = {Singapore EXPO}, github = {TIGER-AI-Lab/MEGA-Bench}, huggingface = {https://huggingface.co/spaces/TIGER-Lab/MEGA-Bench}, twitter = {https://x.com/WenhuChen/status/1846692920117678384}, topics = {Evaluation & Benchmarks | Multimodal Reasoning}, selected = false, num_co_first_author = {3}, }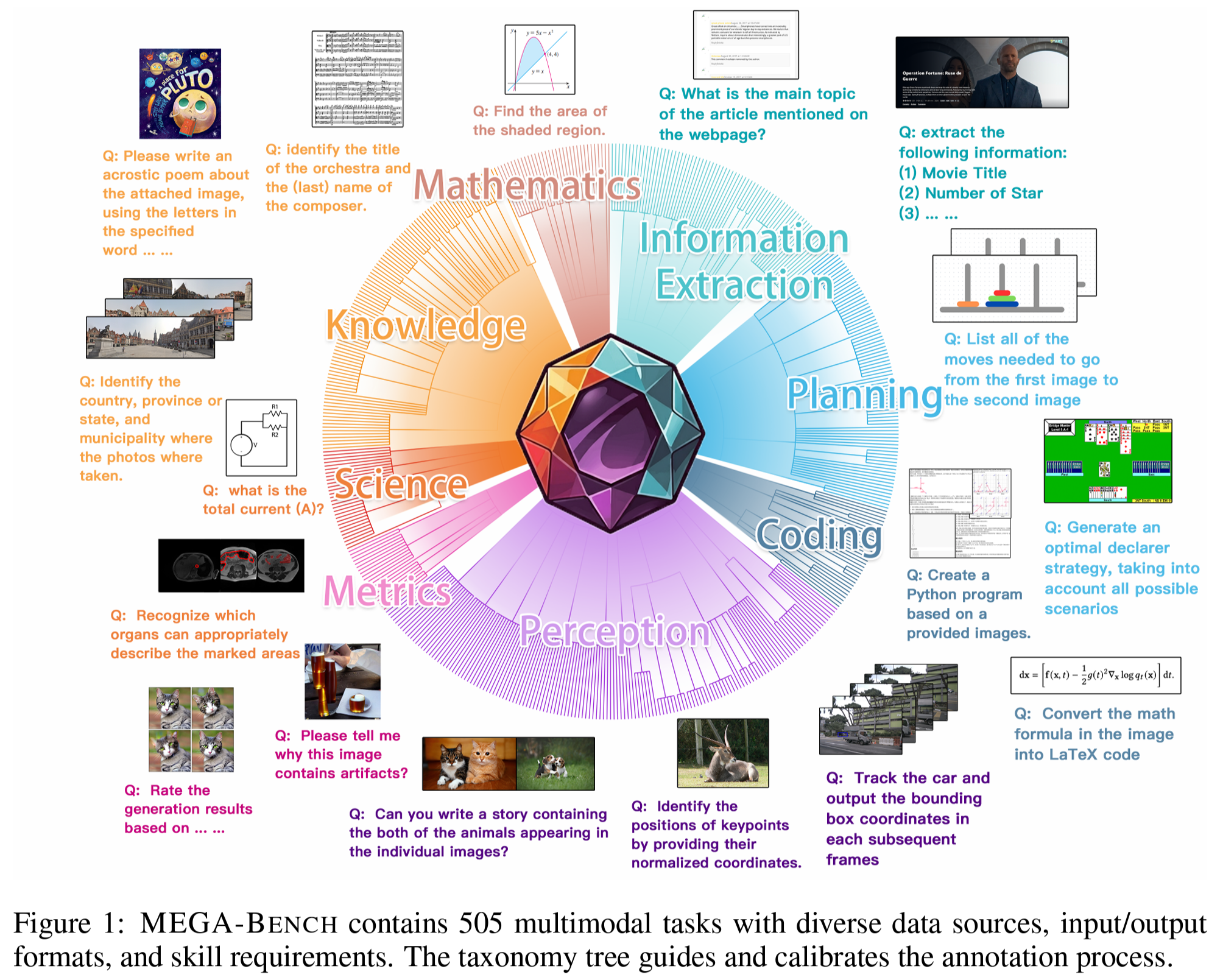
2024
- Xuan He*, Dongfu Jiang*, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, and 11 more authorsNov 2024
The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
@inproceedings{he2024videoscore, title = {VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation}, author = {He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Bill Yuchen and Chen, Wenhu}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.127/}, doi = {10.18653/v1/2024.emnlp-main.127}, pages = {2105--2123}, github = {TIGER-AI-Lab/VideoScore}, huggingface = {https://huggingface.co/collections/TIGER-Lab/videoscore-6678c9451192e834e91cc0bf}, twitter = {https://twitter.com/DongfuJiang/status/1805438506137010326}, topics = {LLM/VLM Post-Training | Evaluation & Benchmarks | Multimodal Reasoning | Reward Models}, selected = false, num_co_first_author = {2}, }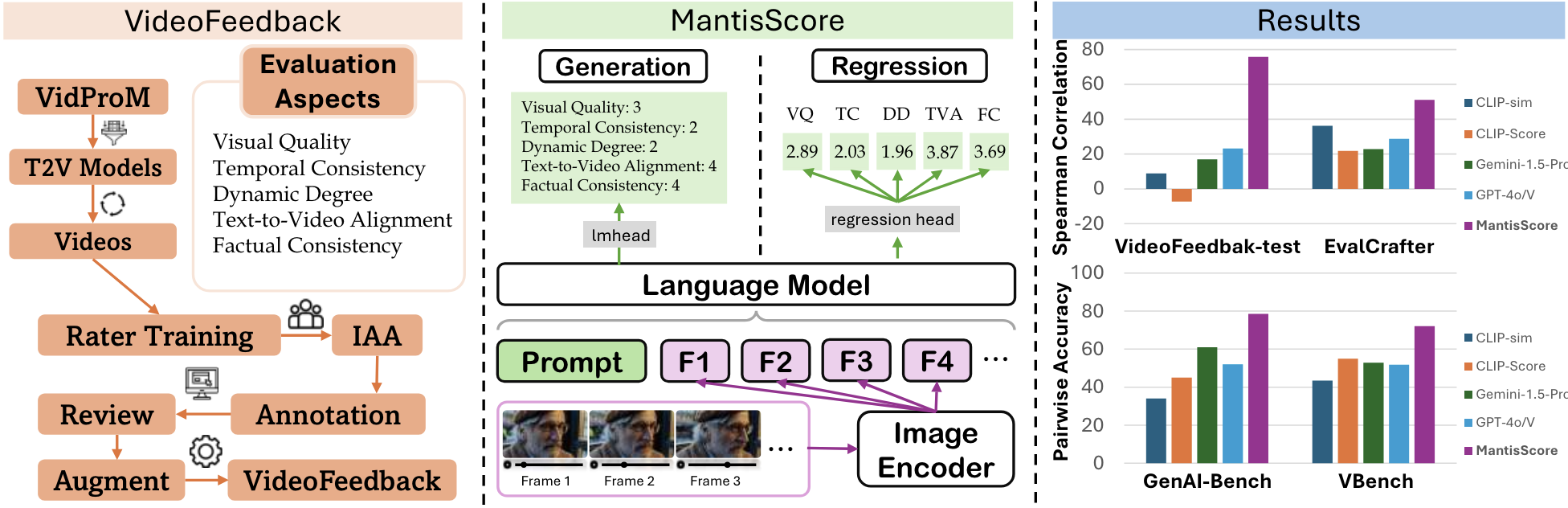
- Dec 2024
Recent breakthroughs in vision-language models (VLMs) emphasize the necessity of benchmarking human preferences in real-world multimodal interactions. To address this gap, we launched WildVision-Arena (WV-Arena), an online platform that collects human preferences to evaluate VLMs. We curated WV-Bench by selecting 500 high-quality samples from 8,000 user submissions in WV-Arena. WV-Bench uses GPT-4 as the judge to compare each VLM with Claude-3-Sonnet, achieving a Spearman correlation of 0.94 with the WV-Arena Elo. This significantly outperforms other benchmarks like MMVet, MMMU, and MMStar. Our comprehensive analysis of 20K real-world interactions reveals important insights into the failure cases of top-performing VLMs. For example, we find that although GPT-4V surpasses many other models like Reka-Flash, Opus, and Yi-VL-Plus in simple visual recognition and reasoning tasks, it still faces challenges with subtle contextual cues, spatial reasoning, visual imagination, and expert domain knowledge. Additionally, current VLMs exhibit issues with hallucinations and safety when intentionally provoked. We are releasing our chat and feedback data to further advance research in the field of VLMs.
@inproceedings{Lu2024WildVisionEV, title = {WildVision: Evaluating Vision-Language Models in the Wild with Human Preferences}, author = {Lu, Yujie and Jiang, Dongfu and Chen, Wenhu and Wang, William Yang and Choi, Yejin and Lin, Bill Yuchen}, booktitle = {Advances in Neural Information Processing Systems 37 (NeurIPS 2024) Datasets and Benchmarks Track}, address = {Vancouver, Canada}, month = dec, year = {2024}, url = {https://proceedings.neurips.cc/paper_files/paper/2024/hash/563991b5c8b45fe75bea42db738223b2-Abstract-Datasets_and_Benchmarks_Track.html}, doi = {10.52202/079017-1528}, github = {WildVision-AI/WildVision-Arena}, twitter = {https://twitter.com/billyuchenlin/status/1755207605537120513}, huggingface = {https://huggingface.co/spaces/WildVision/vision-arena}, topics = {Evaluation & Benchmarks | Multimodal Reasoning}, selected = false, }
- Dongfu Jiang*, Max Ku*, Tianle Li*, Yuansheng Ni, Shizhuo Sun, Rongqi Fan, and Wenhu ChenDec 2024
Generative AI has made remarkable strides to revolutionize fields such as image and video generation. These advancements are driven by innovative algorithms, architecture, and data. However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, FVD, etc often fail to capture the nuanced quality and user satisfaction associated with generative outputs. This paper proposes an open platform \arena to evaluate different image and video generative models, where users can actively participate in evaluating these models. By leveraging collective user feedback and votes, \arena aims to provide a more democratic and accurate measure of model performance. It covers three arenas for text-to-image generation, text-to-video generation, and image editing respectively. Currently, we cover a total of 27 open-source generative models. \arena has been operating for four months, amassing over 6000 votes from the community. We describe our platform, analyze the data, and explain the statistical methods for ranking the models. To further promote the research in building model-based evaluation metrics, we release a cleaned version of our preference data for the three tasks, namely GenAI-Bench. We prompt the existing multi-modal models like Gemini, GPT-4o to mimic human voting. We compute the correlation between model voting with human voting to understand their judging abilities. Our results show existing multimodal models are still lagging in assessing the generated visual content, even the best model GPT-4o only achieves a Pearson correlation of 0.22 in quality subscore, and behave like random guessing in others.
@inproceedings{Jiang2024GenAIAA, title = {GenAI Arena: An Open Evaluation Platform for Generative Models}, author = {Jiang, Dongfu and Ku, Max and Li, Tianle and Ni, Yuansheng and Sun, Shizhuo and Fan, Rongqi and Chen, Wenhu}, booktitle = {Advances in Neural Information Processing Systems 37 (NeurIPS 2024) Datasets and Benchmarks Track}, address = {Vancouver, Canada}, month = dec, year = {2024}, url = {https://proceedings.neurips.cc/paper_files/paper/2024/hash/92249f9233286e437f808fa535d88b26-Abstract-Datasets_and_Benchmarks_Track.html}, doi = {10.52202/079017-2538}, github = {TIGER-AI-Lab/GenAI-Arena}, huggingface = {https://huggingface.co/spaces/TIGER-Lab/GenAI-Arena}, topics = {Evaluation & Benchmarks}, selected = false, num_co_first_author = {3}, }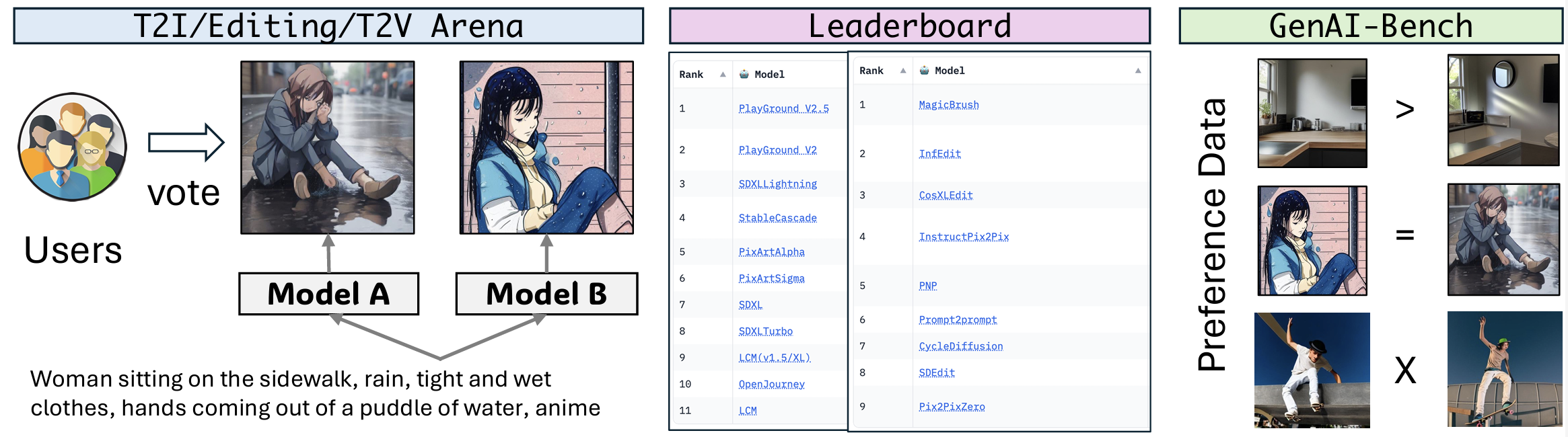
- Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max W.F. Ku, Qian Liu, and Wenhu ChenDec 2024Outstanding Paper Award at TMLR 2025 (1 / 1539 selected)
Large multimodal models (LMMs) have shown great results in single-image vision language tasks. However, their abilities to solve multi-image visual language tasks is yet to be improved. The existing LMMs like OpenFlamingo, Emu2, Idefics gain their multi-image ability through pre-training on hundreds of millions of noisy interleaved image-text data from the web, which is neither efficient nor effective. In this paper, we aim to build strong multi-image LMMs via instruction tuning with academic-level resources. Therefore, we meticulously construct Mantis-Instruct containing 721K multi-image instruction data to train a family of models Mantis. The instruction tuning empowers Mantis with different multi-image skills like co-reference, comparison, reasoning, and temporal understanding. We evaluate Mantis on five multi-image benchmarks and seven single-image benchmarks. Mantis-SigLIP can achieve SoTA results on all the multi-image benchmarks and beat the strongest multi-image baseline, Idefics2-8B by an average of 11 absolute points. Notably, Idefics2-8B was pre-trained on 140M interleaved multi-image data, which is 200x larger than Mantis-Instruct. We observe that Mantis performs equivalently well on the held-in and held-out benchmarks, which shows its generalization ability. Notably, we found that Mantis can even match the performance of GPT-4V on multi-image benchmarks. We further evaluate Mantis on single-image benchmarks and demonstrate that Mantis also maintains a strong single-image performance on par with CogVLM and Emu2. Our results show that multi-image abilities are not necessarily gained through massive pre-training, instead, it can be gained by the low-cost instruction tuning. Our work provides new perspectives on how to improve LMMs’ multi-image abilities.
@article{Jiang2024MANTISIM, title = {MANTIS: Interleaved Multi-Image Instruction Tuning}, author = {Jiang, Dongfu and He, Xuan and Zeng, Huaye and Wei, Cong and Ku, Max W.F. and Liu, Qian and Chen, Wenhu}, journal = {Transactions on Machine Learning Research}, year = {2024}, eprint = {2405.01483}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://openreview.net/forum?id=skLtdUVaJa}, github = {TIGER-AI-Lab/Mantis}, twitter = {https://twitter.com/DongfuJiang/status/1786552974598078677}, huggingface = {https://huggingface.co/collections/TIGER-Lab/mantis-6619b0834594c878cdb1d6e4}, topics = {LLM/VLM Post-Training | Multimodal Reasoning | Evaluation & Benchmarks}, selected = true, highlight = {Outstanding Paper Award at TMLR 2025 (1 / 1539 selected)}, }
- Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu ChenAug 2024
In the rapidly advancing field of conditional image generation research, challenges such as limited explainability lie in effectively evaluating the performance and capabilities of various models. This paper introduces VIEScore, a Visual Instruction-guided Explainable metric for evaluating any conditional image generation tasks. VIEScore leverages general knowledge from Multimodal Large Language Models (MLLMs) as the backbone and does not require training or fine-tuning. We evaluate VIEScore on seven prominent tasks in conditional image tasks and found: (1) VIEScore (GPT4-o) achieves a high Spearman correlation of 0.4 with human evaluations, while the human-to-human correlation is 0.45. (2) VIEScore (with open-source MLLM) is significantly weaker than GPT-4o and GPT-4v in evaluating synthetic images. (3) VIEScore achieves a correlation on par with human ratings in the generation tasks but struggles in editing tasks. With these results, we believe VIEScore shows its great potential to replace human judges in evaluating image synthesis tasks.
@inproceedings{Ku2023VIEScoreTE, title = {VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation}, author = {Ku, Max and Jiang, Dongfu and Wei, Cong and Yue, Xiang and Chen, Wenhu}, booktitle = {Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, publisher = {Association for Computational Linguistics}, month = aug, year = {2024}, address = {Bangkok, Thailand}, url = {https://aclanthology.org/2024.acl-long.663}, doi = {10.18653/v1/2024.acl-long.663}, pages = {12268--12290}, github = {TIGER-AI-Lab/VIEScore}, twitter = {https://twitter.com/DongfuJiang/status/1742043191732302076}, topics = {Evaluation & Benchmarks}, selected = false, }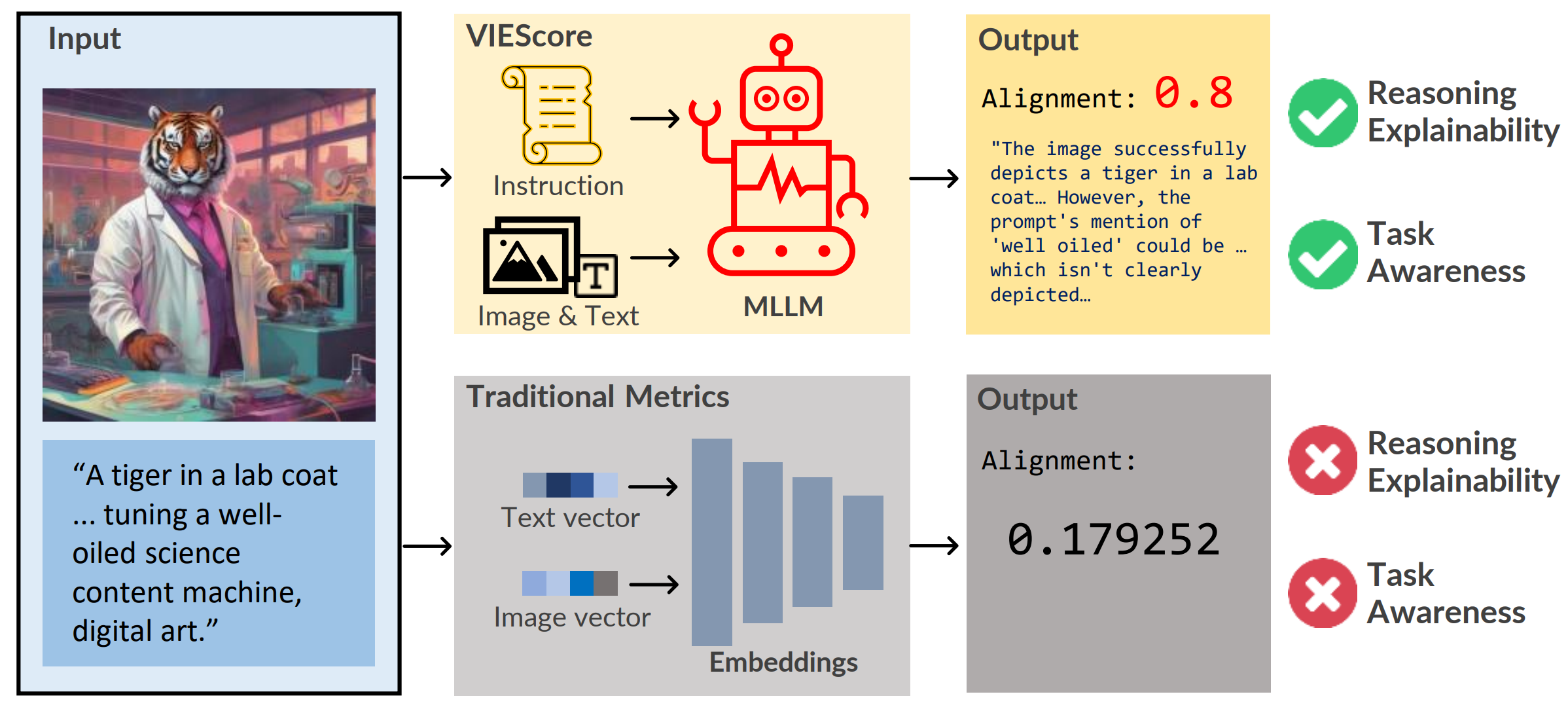
- Xiang Yue*, Yuansheng Ni*, Kai Zhang*, Tianyu Zheng*, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, and 14 more authorsJun 2024Best Paper Finalist and Oral at CVPR 2024 (24 / 11,532 selected)
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams quizzes and textbooks covering six core disciplines: Art & Design Business Science Health & Medicine Humanities & Social Science and Tech & Engineering. These questions span 30 subjects and 183 subfields comprising 30 highly heterogeneous image types such as charts diagrams maps tables music sheets and chemical structures. Unlike existing benchmarks MMMU focuses on advanced perception and reasoning with domain-specific knowledge challenging models to perform tasks akin to those faced by experts. The evaluation of 28 open-source LMMs as well as the proprietary GPT-4V(ision) and Gemini highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V and Gemini Ultra only achieve accuracies of 56% and 59% respectively indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
@inproceedings{Yue2023MMMUAM, title = {MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI}, author = {Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and Wei, Cong and Yu, Botao and Yuan, Ruibin and Sun, Renliang and Yin, Ming and Zheng, Boyuan and Yang, Zhenzhu and Liu, Yibo and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu}, month = jun, address = {Seattle, Washington, USA}, year = {2024}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, url = {https://openaccess.thecvf.com/content/CVPR2024/html/Yue_MMMU_A_Massive_Multi-discipline_Multimodal_Understanding_and_Reasoning_Benchmark_for_CVPR_2024_paper.html}, pages = {9556--9567}, github = {MMMU-Benchmark/MMMU}, twitter = {https://twitter.com/xiangyue96/status/1729698316554801358}, huggingface = {https://huggingface.co/datasets/MMMU/MMMU}, topics = {Evaluation & Benchmarks | Multimodal Reasoning}, selected = true, highlight = {Best Paper Finalist and Oral at CVPR 2024 (24 / 11,532 selected)}, num_co_first_author = {4} }
- Dongfu Jiang*, Yishan Li*, Ge Zhang, Wenhao Huang, Bill Yuchen Lin, and Wenhu ChenMay 2024
We present TIGERScore, a \textbfTrained metric that follows \textbfInstruction \textbfGuidance to perform \textbfExplainable, and \textbfReference-free evaluation over a wide spectrum of text generation tasks. Different from other automatic evaluation methods that only provide arcane scores, TIGERScore is guided by natural language instruction to provide error analysis to pinpoint the mistakes in the generated text. Our metric is based on LLaMA-2, trained on our meticulously curated instruction-tuning dataset MetricInstruct which covers 6 text generation tasks and 23 text generation datasets. The dataset consists of 42K quadruple in the form of (instruction, input, system output error analysis). We collected the ‘system outputs’ through from a large variety of models to cover different types of errors. To quantitatively assess our metric, we evaluate its correlation with human ratings on 5 held-in datasets, 2 held-out datasets and show that \metricname can achieve the open-source SoTA correlation with human ratings across these datasets and almost approaches GPT-4 evaluator. As a reference-free metric, its correlation can even surpass the best existing reference-based metrics. To further qualitatively assess the rationale generated by our metric, we conduct human evaluation on the generated explanations and found that the explanations are 70.8% accurate. Through these experimental results, we believe \metricname demonstrates the possibility of building universal explainable metrics to evaluate any text generation task.
@article{jiang2024tigerscore, title = {{TIGERS}core: Towards Building Explainable Metric for All Text Generation Tasks}, author = {Jiang, Dongfu and Li, Yishan and Zhang, Ge and Huang, Wenhao and Lin, Bill Yuchen and Chen, Wenhu}, journal = {Transactions on Machine Learning Research}, year = {2024}, month = may, selected = false, github = {TIGER-AI-Lab/TIGERScore}, twitter = {https://twitter.com/DongfuJiang/status/1735508082510168425}, huggingface = {https://huggingface.co/collections/TIGER-Lab/tigerscore-657020bfae61260b6131f1ca}, issn = {2835-8856}, url = {https://openreview.net/forum?id=EE1CBKC0SZ}, topics = {Evaluation & Benchmarks}, num_co_first_author = {2} }
2023
- Dongfu Jiang, Xiang Ren, and Bill Yuchen LinJul 2023
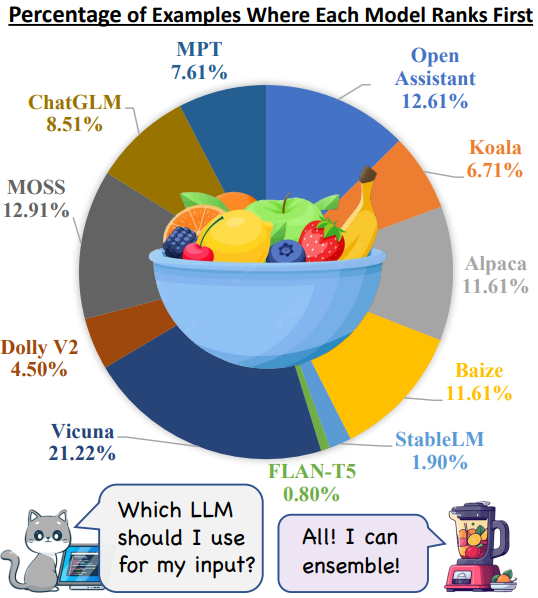
We present LLM-Blender, an ensembling framework designed to attain consistently superior performance by leveraging the diverse strengths of multiple open-source large language models (LLMs). Our framework consists of two modules: PairRanker and GenFuser, addressing the observation that optimal LLMs for different examples can significantly vary. PairRanker employs a specialized pairwise comparison method to distinguish subtle differences between candidate outputs. It jointly encodes the input text and a pair of candidates, using cross-attention encoders to determine the superior one. Our results demonstrate that PairRanker exhibits the highest correlation with ChatGPT-based ranking. Then, GenFuser aims to merge the top-ranked candidates, generating an improved output by capitalizing on their strengths and mitigating their weaknesses. To facilitate large-scale evaluation, we introduce a benchmark dataset, MixInstruct, which is a mixture of multiple instruction datasets featuring oracle pairwise comparisons. Our LLM-Blender significantly outperform individual LLMs and baseline methods across various metrics, establishing a substantial performance gap.
@inproceedings{jiang-etal-2023-llm, title = {{LLM}-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion}, author = {Jiang, Dongfu and Ren, Xiang and Lin, Bill Yuchen}, booktitle = {Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.acl-long.792}, doi = {10.18653/v1/2023.acl-long.792}, pages = {14165--14178}, selected = true, github = {yuchenlin/LLM-Blender}, twitter = {https://twitter.com/billyuchenlin/status/1668666357058277377}, huggingface = {https://huggingface.co/llm-blender}, topics = {Reward Models | Agentic Systems}, }